 3D Representations
3D Representations
Neural Radiance Field
Introduced by Mildenhall et al. in NeRF: Representing Scenes as Neural Radiance Fields for View SynthesisNeRF represents a scene with learned, continuous volumetric radiance field $F_\theta$ defined over a bounded 3D volume. In a NeRF, $F_\theta$ is a multilayer perceptron (MLP) that takes as input a 3D position $x = (x, y, z)$ and unit-norm viewing direction $d = (dx, dy, dz)$, and produces as output a density $\sigma$ and color $c = (r, g, b)$. The weights of the multilayer perceptron that parameterize $F_\theta$ are optimized so as to encode the radiance field of the scene. Volume rendering is used to compute the color of a single pixel.
Source: NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis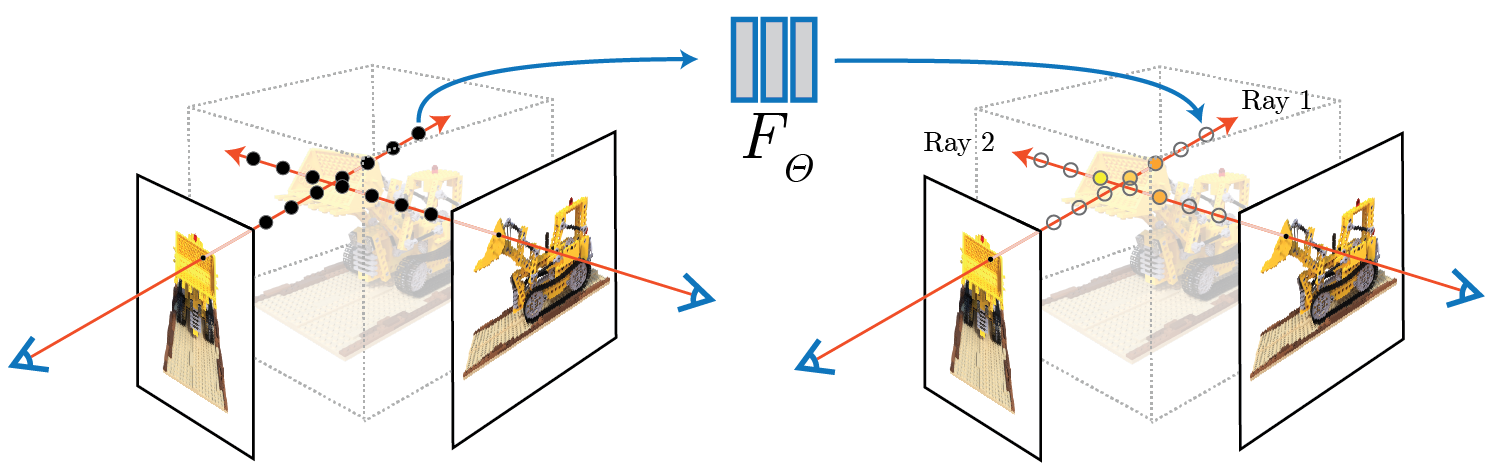
Papers
| Paper | Code | Results | Date | Stars |
|---|
Tasks
| Task | Papers | Share |
|---|---|---|
| Novel View Synthesis | 141 | 21.53% |
| 3D Reconstruction | 53 | 8.09% |
| Neural Rendering | 31 | 4.73% |
| Text to 3D | 27 | 4.12% |
| 3D Generation | 25 | 3.82% |
| Depth Estimation | 19 | 2.90% |
| Image Generation | 18 | 2.75% |
| Pose Estimation | 18 | 2.75% |
| Semantic Segmentation | 18 | 2.75% |
Usage Over Time
Components
| Component | Type |
|
|---|---|---|
| 🤖 No Components Found | You can add them if they exist; e.g. Mask R-CNN uses RoIAlign |
