Compositional Embeddings Using Complementary Partitions for Memory-Efficient Recommendation Systems
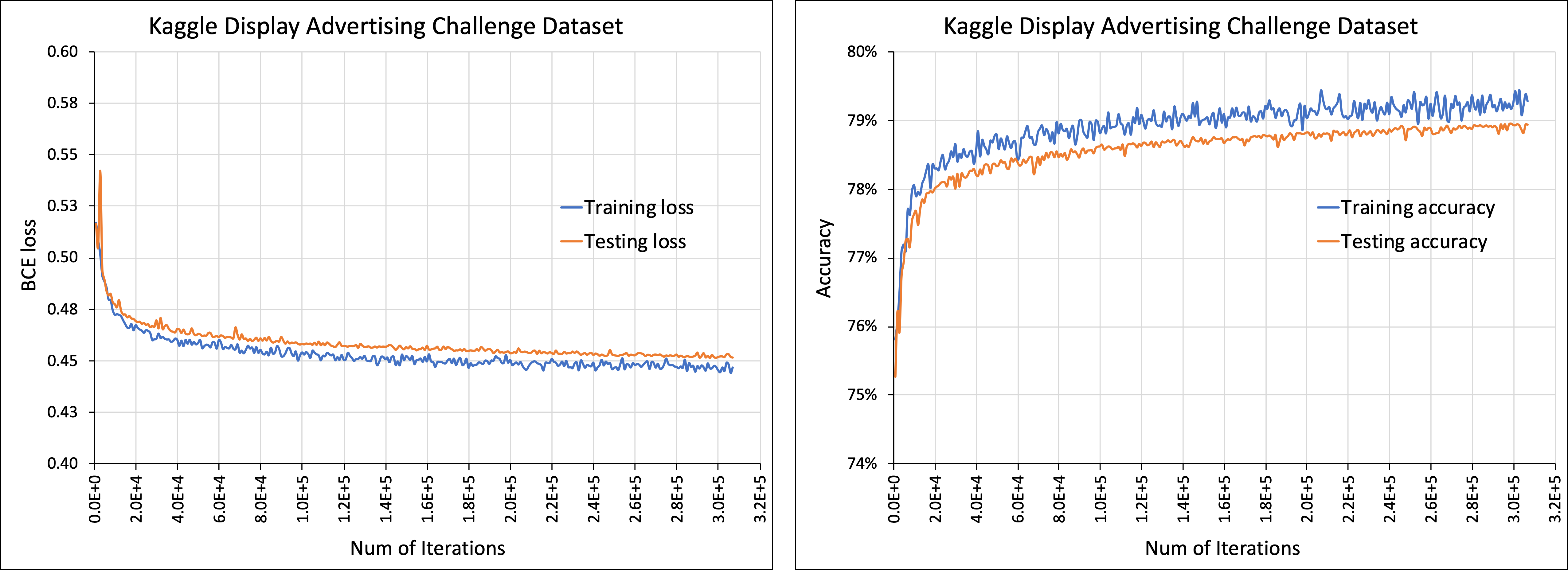
Modern deep learning-based recommendation systems exploit hundreds to thousands of different categorical features, each with millions of different categories ranging from clicks to posts. To respect the natural diversity within the categorical data, embeddings map each category to a unique dense representation within an embedded space. Since each categorical feature could take on as many as tens of millions of different possible categories, the embedding tables form the primary memory bottleneck during both training and inference. We propose a novel approach for reducing the embedding size in an end-to-end fashion by exploiting complementary partitions of the category set to produce a unique embedding vector for each category without explicit definition. By storing multiple smaller embedding tables based on each complementary partition and combining embeddings from each table, we define a unique embedding for each category at smaller memory cost. This approach may be interpreted as using a specific fixed codebook to ensure uniqueness of each category's representation. Our experimental results demonstrate the effectiveness of our approach over the hashing trick for reducing the size of the embedding tables in terms of model loss and accuracy, while retaining a similar reduction in the number of parameters.
PDF Abstract

