Control Variates for Slate Off-Policy Evaluation
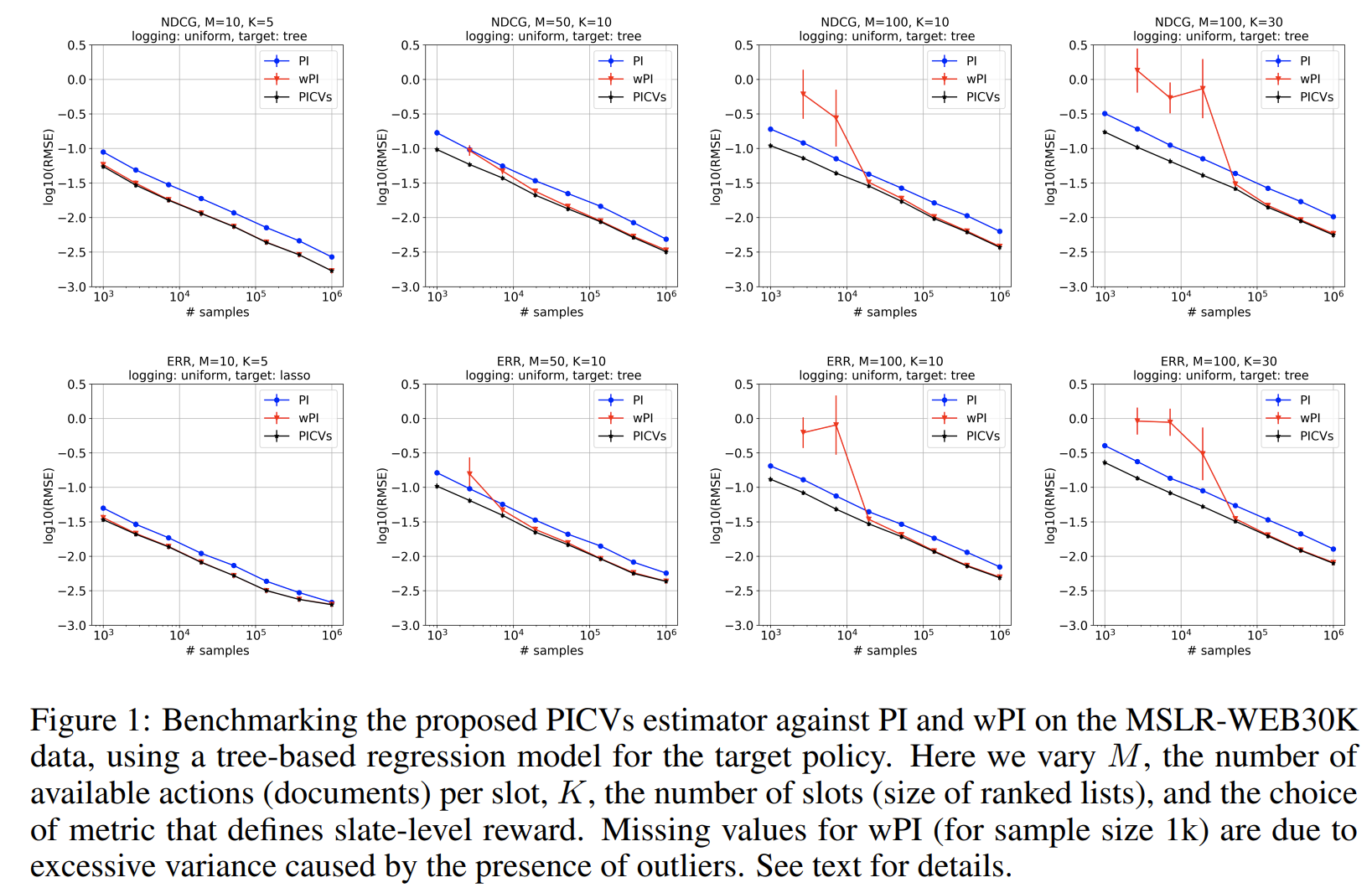
We study the problem of off-policy evaluation from batched contextual bandit data with multidimensional actions, often termed slates. The problem is common to recommender systems and user-interface optimization, and it is particularly challenging because of the combinatorially-sized action space. Swaminathan et al. (2017) have proposed the pseudoinverse (PI) estimator under the assumption that the conditional mean rewards are additive in actions. Using control variates, we consider a large class of unbiased estimators that includes as specific cases the PI estimator and (asymptotically) its self-normalized variant. By optimizing over this class, we obtain new estimators with risk improvement guarantees over both the PI and the self-normalized PI estimators. Experiments with real-world recommender data as well as synthetic data validate these improvements in practice.
PDF Abstract NeurIPS 2021 PDF NeurIPS 2021 Abstract

