DARA: Domain- and Relation-aware Adapters Make Parameter-efficient Tuning for Visual Grounding
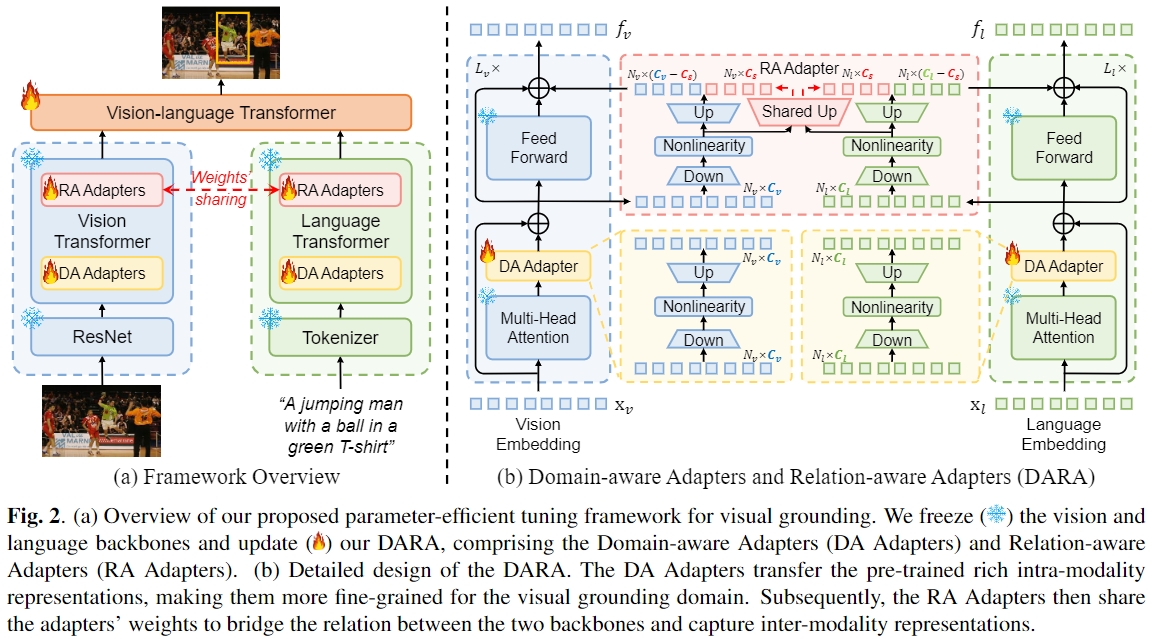
Visual grounding (VG) is a challenging task to localize an object in an image based on a textual description. Recent surge in the scale of VG models has substantially improved performance, but also introduced a significant burden on computational costs during fine-tuning. In this paper, we explore applying parameter-efficient transfer learning (PETL) to efficiently transfer the pre-trained vision-language knowledge to VG. Specifically, we propose \textbf{DARA}, a novel PETL method comprising \underline{\textbf{D}}omain-aware \underline{\textbf{A}}dapters (DA Adapters) and \underline{\textbf{R}}elation-aware \underline{\textbf{A}}dapters (RA Adapters) for VG. DA Adapters first transfer intra-modality representations to be more fine-grained for the VG domain. Then RA Adapters share weights to bridge the relation between two modalities, improving spatial reasoning. Empirical results on widely-used benchmarks demonstrate that DARA achieves the best accuracy while saving numerous updated parameters compared to the full fine-tuning and other PETL methods. Notably, with only \textbf{2.13\%} tunable backbone parameters, DARA improves average accuracy by \textbf{0.81\%} across the three benchmarks compared to the baseline model. Our code is available at \url{https://github.com/liuting20/DARA}.
PDF Abstract



