Data-Informed Global Sparseness in Attention Mechanisms for Deep Neural Networks
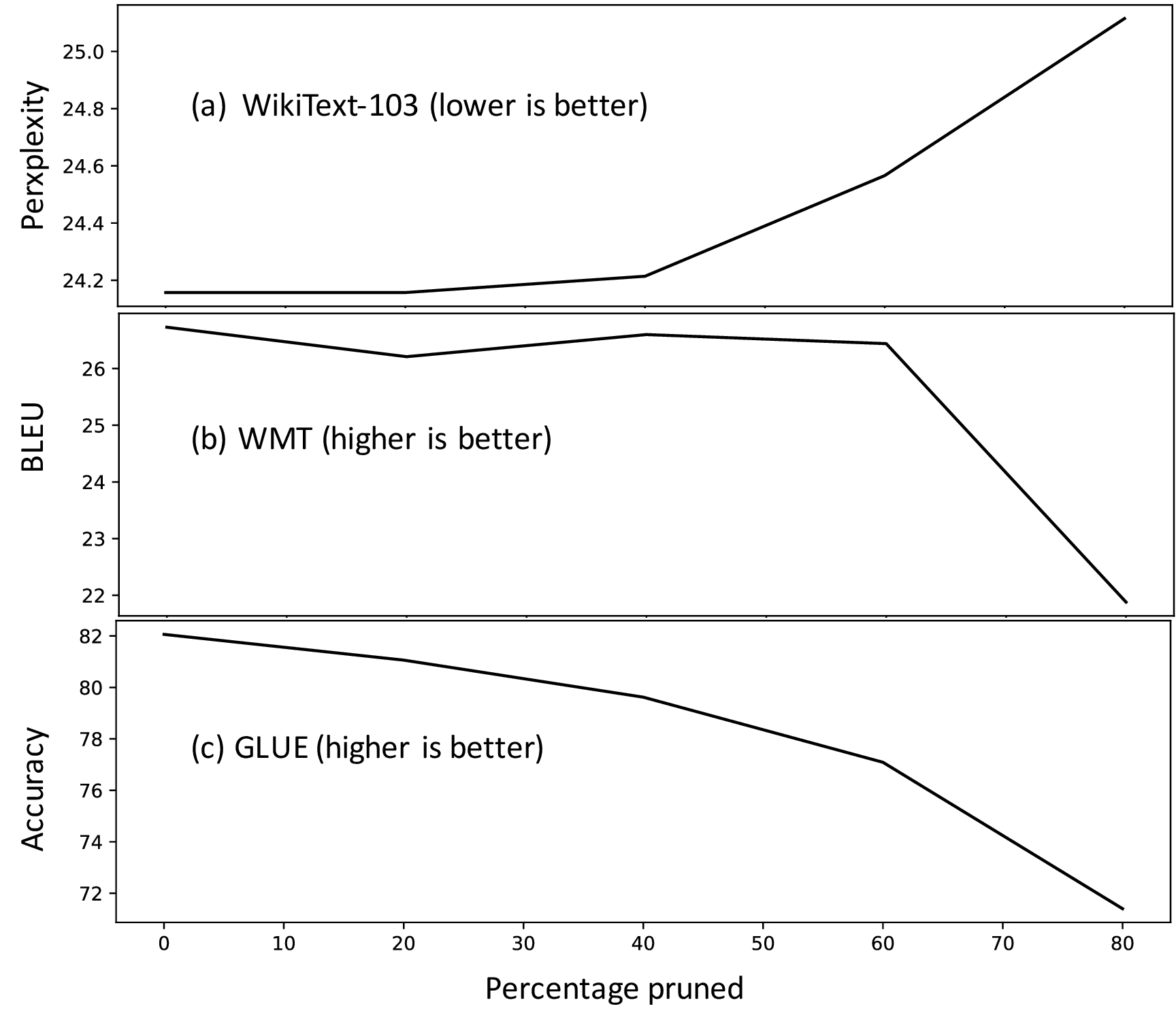
Attention mechanisms play a crucial role in the neural revolution of Natural Language Processing (NLP). With the growth of attention-based models, several pruning techniques have been developed to identify and exploit sparseness, making these models more efficient. Most efforts focus on hard-coding attention patterns or pruning attention weights based on training data. We propose Attention Pruning (AP), a framework that observes attention patterns in a fixed dataset and generates a global sparseness mask. AP saves 90% of attention computation for language modeling and about 50% for machine translation and GLUE tasks, maintaining result quality. Our method reveals important distinctions between self- and cross-attention patterns, guiding future NLP research. Our framework can reduce both latency and memory requirements for any attention-based model, aiding in the development of improved models for existing or new NLP applications. We have demonstrated this with encoder and autoregressive transformer models using Triton GPU kernels and make our code publicly available at https://github.com/irugina/AP.
PDF Abstract



 GLUE
GLUE
 SST
SST
 SQuAD
SQuAD
 MultiNLI
MultiNLI
 QNLI
QNLI
 WikiText-2
WikiText-2
 MRPC
MRPC
 CoLA
CoLA
 WikiText-103
WikiText-103
