Deep Instruction Tuning for Segment Anything Model
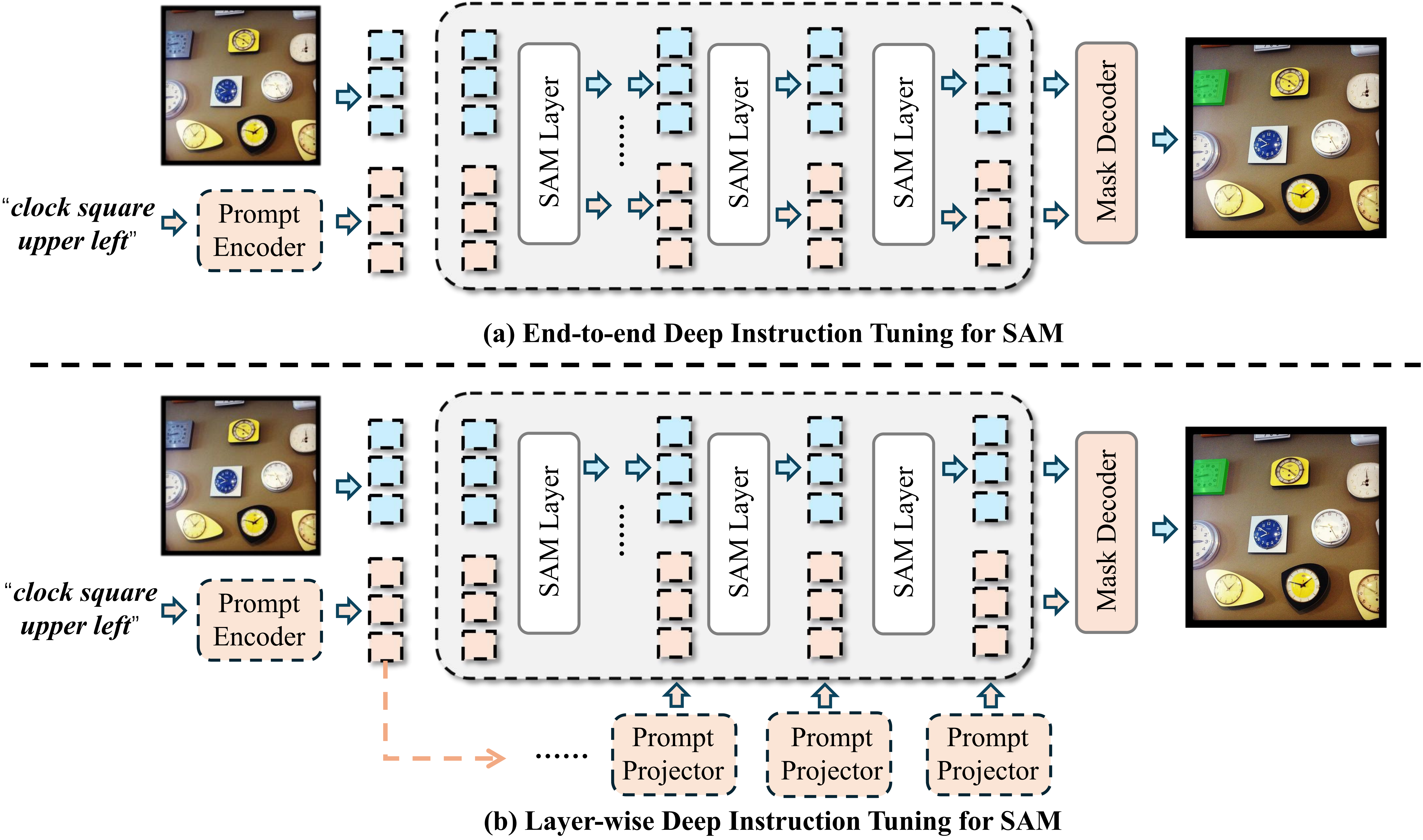
Recently, Segment Anything Model (SAM) has become a research hotspot in the fields of multimedia and computer vision, which exhibits powerful yet versatile capabilities on various (un) conditional image segmentation tasks. Although SAM can support different types of segmentation prompts, we note that, compared to point- and box-guided segmentations, it performs much worse on text-instructed tasks, e.g., referring image segmentation (RIS). In this paper, we argue that deep text instruction tuning is key to mitigate such shortcoming caused by the shallow fusion scheme in its default light-weight mask decoder. To address this issue, we propose two simple yet effective deep instruction tuning (DIT) methods for SAM, one is end-to-end and the other is layer-wise. With minimal modifications, DITs can directly transform the image encoder of SAM as a stand-alone vision-language learner in contrast to building another deep fusion branch, maximizing the benefit of its superior segmentation capability. Extensive experiments on three highly competitive benchmark datasets of RIS show that a simple end-to-end DIT can improve SAM by a large margin, while the layer-wise DIT can further boost the performance to state-of-the-art with much less data and training expenditures. Our code is released at: https://github.com/wysnzzzz/DIT.
PDF Abstract


 MS COCO
MS COCO
 RefCOCO
RefCOCO
