Deep is a Luxury We Don't Have
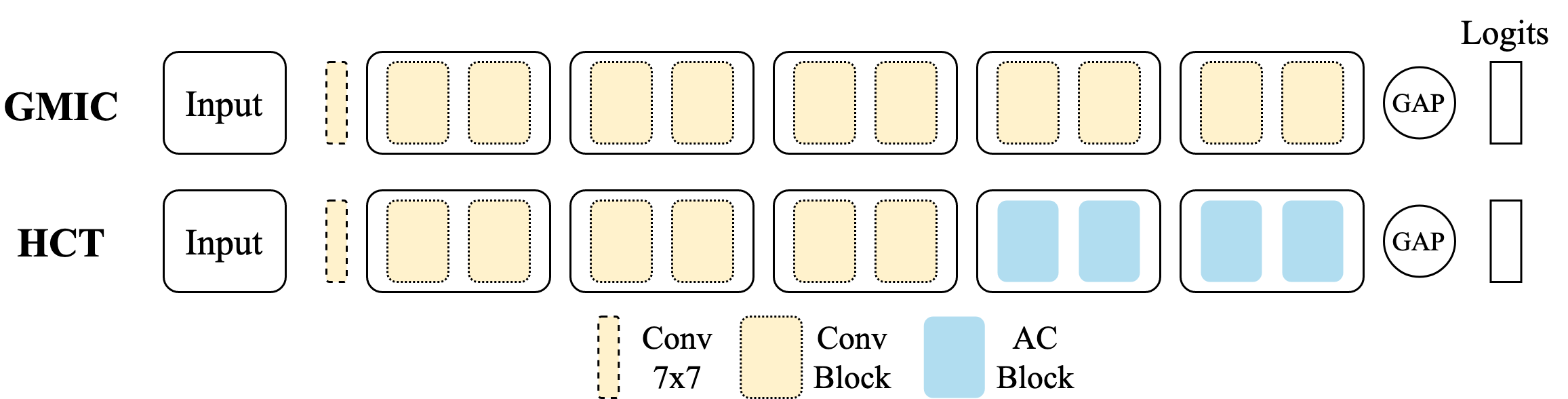
Medical images come in high resolutions. A high resolution is vital for finding malignant tissues at an early stage. Yet, this resolution presents a challenge in terms of modeling long range dependencies. Shallow transformers eliminate this problem, but they suffer from quadratic complexity. In this paper, we tackle this complexity by leveraging a linear self-attention approximation. Through this approximation, we propose an efficient vision model called HCT that stands for High resolution Convolutional Transformer. HCT brings transformers' merits to high resolution images at a significantly lower cost. We evaluate HCT using a high resolution mammography dataset. HCT is significantly superior to its CNN counterpart. Furthermore, we demonstrate HCT's fitness for medical images by evaluating its effective receptive field.Code available at https://bit.ly/3ykBhhf
PDF Abstract
