Exploiting temporal consistency for real-time video depth estimation
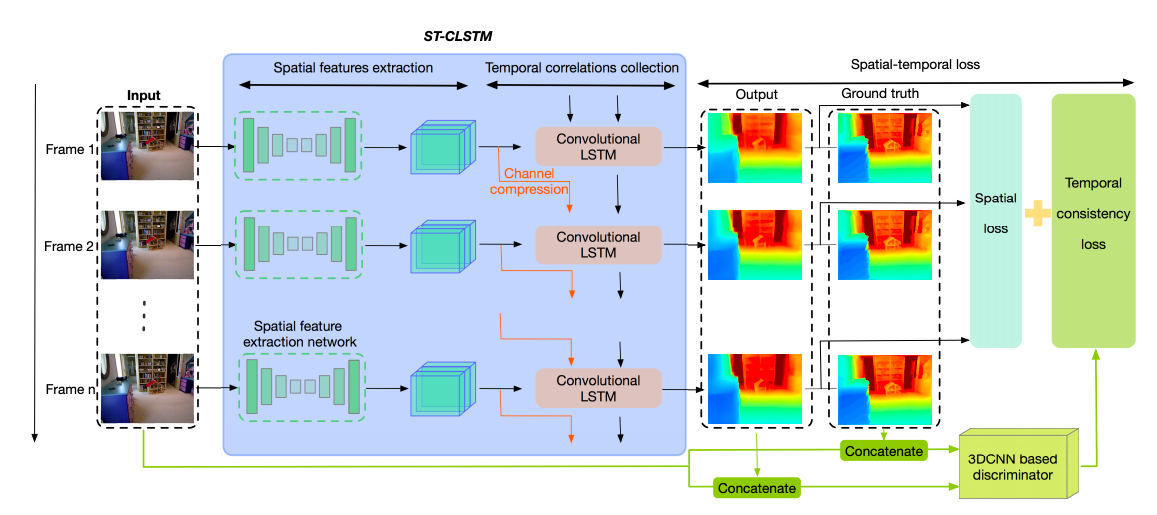
Accuracy of depth estimation from static images has been significantly improved recently, by exploiting hierarchical features from deep convolutional neural networks (CNNs). Compared with static images, vast information exists among video frames and can be exploited to improve the depth estimation performance. In this work, we focus on exploring temporal information from monocular videos for depth estimation. Specifically, we take the advantage of convolutional long short-term memory (CLSTM) and propose a novel spatial-temporal CSLTM (ST-CLSTM) structure. Our ST-CLSTM structure can capture not only the spatial features but also the temporal correlations/consistency among consecutive video frames with negligible increase in computational cost. Additionally, in order to maintain the temporal consistency among the estimated depth frames, we apply the generative adversarial learning scheme and design a temporal consistency loss. The temporal consistency loss is combined with the spatial loss to update the model in an end-to-end fashion. By taking advantage of the temporal information, we build a video depth estimation framework that runs in real-time and generates visually pleasant results. Moreover, our approach is flexible and can be generalized to most existing depth estimation frameworks. Code is available at: https://tinyurl.com/STCLSTM
PDF Abstract ICCV 2019 PDF ICCV 2019 Abstract


 Mid-Air Dataset
Mid-Air Dataset

