Fashionformer: A simple, Effective and Unified Baseline for Human Fashion Segmentation and Recognition
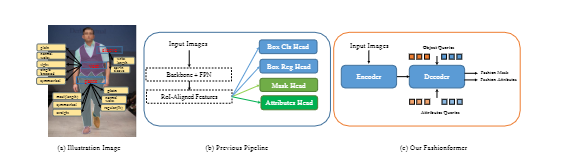
Human fashion understanding is one crucial computer vision task since it has comprehensive information for real-world applications. This focus on joint human fashion segmentation and attribute recognition. Contrary to the previous works that separately model each task as a multi-head prediction problem, our insight is to bridge these two tasks with one unified model via vision transformer modeling to benefit each task. In particular, we introduce the object query for segmentation and the attribute query for attribute prediction. Both queries and their corresponding features can be linked via mask prediction. Then we adopt a two-stream query learning framework to learn the decoupled query representations.We design a novel Multi-Layer Rendering module for attribute stream to explore more fine-grained features. The decoder design shares the same spirit as DETR. Thus we name the proposed method \textit{Fahsionformer}. Extensive experiments on three human fashion datasets illustrate the effectiveness of our approach. In particular, our method with the same backbone achieve \textbf{relative 10\% improvements} than previous works in case of \textit{a joint metric (AP$^{\text{mask}}_{\text{IoU+F}_1}$) for both segmentation and attribute recognition}. To the best of our knowledge, we are the first unified end-to-end vision transformer framework for human fashion analysis. We hope this simple yet effective method can serve as a new flexible baseline for fashion analysis. Code is available at https://github.com/xushilin1/FashionFormer.
PDF Abstract

 MS COCO
MS COCO
 DeepFashion
DeepFashion
 ModaNet
ModaNet
