Fully automated landmarking and facial segmentation on 3D photographs
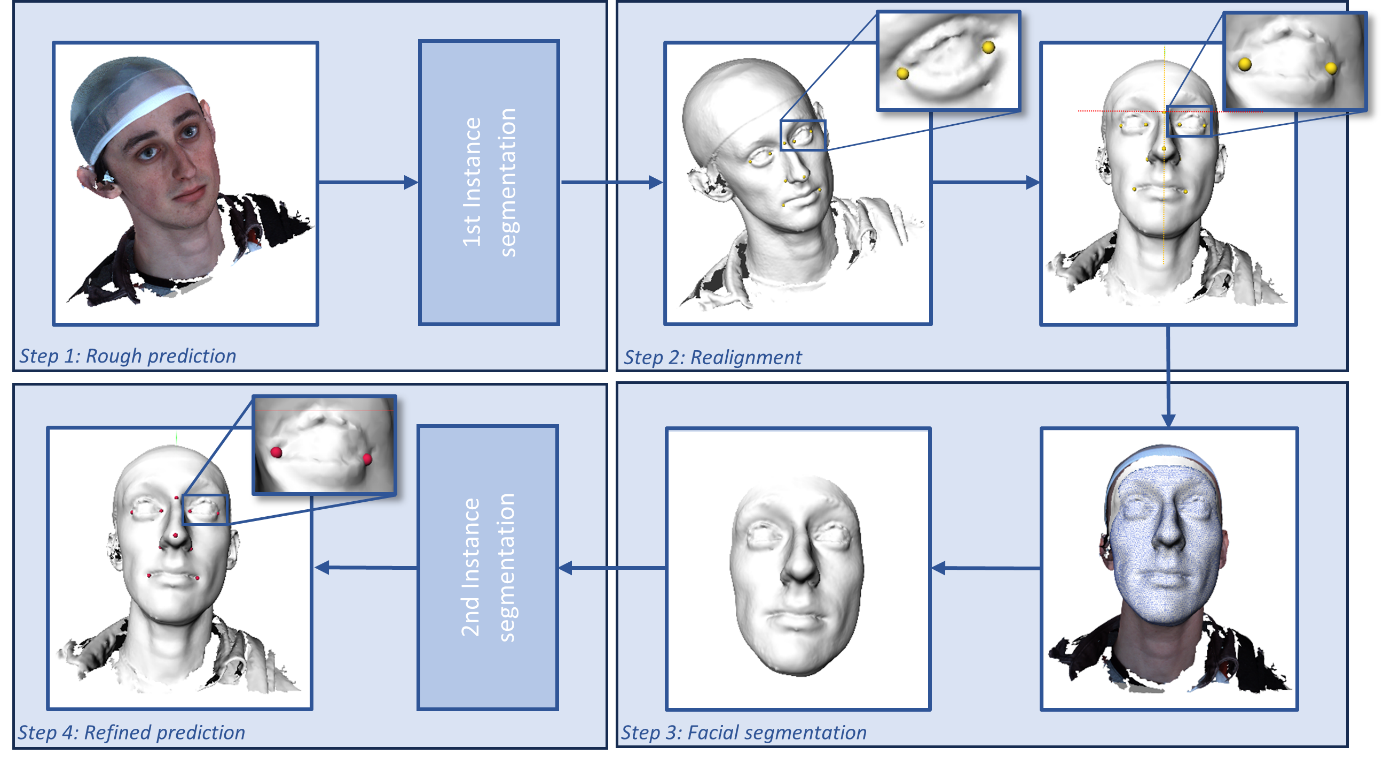
Three-dimensional facial stereophotogrammetry provides a detailed representation of craniofacial soft tissue without the use of ionizing radiation. While manual annotation of landmarks serves as the current gold standard for cephalometric analysis, it is a time-consuming process and is prone to human error. The aim in this study was to develop and evaluate an automated cephalometric annotation method using a deep learning-based approach. Ten landmarks were manually annotated on 2897 3D facial photographs by a single observer. The automated landmarking workflow involved two successive DiffusionNet models and additional algorithms for facial segmentation. The dataset was randomly divided into a training and test dataset. The training dataset was used to train the deep learning networks, whereas the test dataset was used to evaluate the performance of the automated workflow. The precision of the workflow was evaluated by calculating the Euclidean distances between the automated and manual landmarks and compared to the intra-observer and inter-observer variability of manual annotation and the semi-automated landmarking method. The workflow was successful in 98.6% of all test cases. The deep learning-based landmarking method achieved precise and consistent landmark annotation. The mean precision of 1.69 (+/-1.15) mm was comparable to the inter-observer variability (1.31 +/-0.91 mm) of manual annotation. The Euclidean distance between the automated and manual landmarks was within 2 mm in 69%. Automated landmark annotation on 3D photographs was achieved with the DiffusionNet-based approach. The proposed method allows quantitative analysis of large datasets and may be used in diagnosis, follow-up, and virtual surgical planning.
PDF Abstract
