GLaPE: Gold Label-agnostic Prompt Evaluation and Optimization for Large Language Model
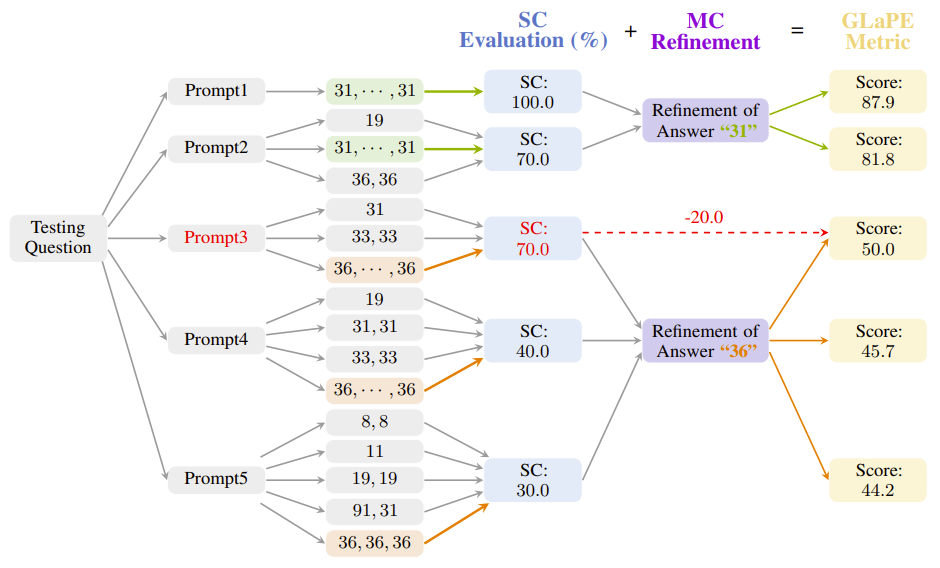
Despite the rapid progress of large language models (LLMs), their task performance remains sensitive to prompt design. Recent studies have explored leveraging the LLM itself as an optimizer to identify optimal prompts that maximize task accuracy. However, when evaluating prompts, such approaches heavily rely on elusive manually annotated gold labels to calculate task accuracy for each candidate prompt, which hinders the widespread implementation and generality. To overcome the limitation, this work proposes a gold label-agnostic prompt evaluation (GLaPE) to alleviate dependence on gold labels. Motivated by the observed correlation between self-consistency and the accuracy of the answer, we adopt self-consistency as the initial evaluation score. Subsequently, we refine the scores of prompts producing identical answers to be mutually consistent. Experimental results show that GLaPE provides reliable evaluations uniform with accuracy, even in the absence of gold labels. Moreover, on six popular reasoning tasks, our GLaPE-based prompt optimization yields effective prompts comparable to accuracy-based ones. The code is publicly available at https://github.com/thunderous77/GLaPE.
PDF Abstract


 GSM8K
GSM8K
 BIG-bench
BIG-bench
 SVAMP
SVAMP
