Knowledge Unlearning for Mitigating Privacy Risks in Language Models
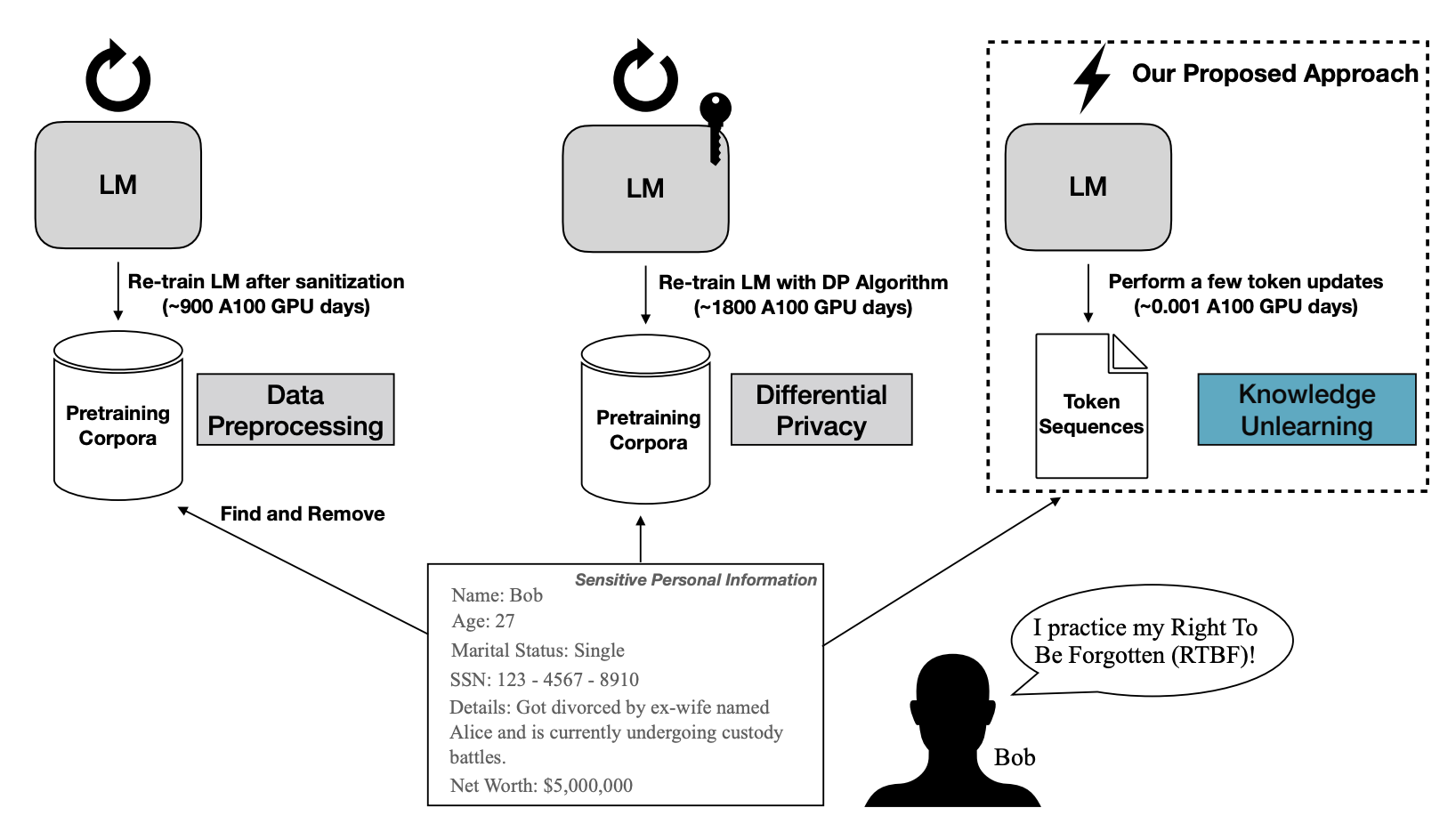
Pretrained Language Models (LMs) memorize a vast amount of knowledge during initial pretraining, including information that may violate the privacy of personal lives and identities. Previous work addressing privacy issues for language models has mostly focused on data preprocessing and differential privacy methods, both requiring re-training the underlying LM. We propose knowledge unlearning as an alternative method to reduce privacy risks for LMs post hoc. We show that simply performing gradient ascent on target token sequences is effective at forgetting them with little to no degradation of general language modeling performances for larger LMs; it sometimes even substantially improves the underlying LM with just a few iterations. We also find that sequential unlearning is better than trying to unlearn all the data at once and that unlearning is highly dependent on which kind of data (domain) is forgotten. By showing comparisons with a previous data preprocessing method and a decoding method known to mitigate privacy risks for LMs, we show that unlearning can give a stronger empirical privacy guarantee in scenarios where the data vulnerable to extraction attacks are known a priori while being much more efficient and robust. We release the code and dataset needed to replicate our results at https://github.com/joeljang/knowledge-unlearning.
PDF Abstract
Tasks

 HellaSwag
HellaSwag
 PIQA
PIQA
 WinoGrande
WinoGrande
 The Pile
The Pile
 COPA
COPA
 LAMBADA
LAMBADA
 PubMedQA
PubMedQA
 Wizard of Wikipedia
Wizard of Wikipedia
 MathQA
MathQA
Results from the Paper
 Ranked #3 on
Language Modelling
on The Pile
(Test perplexity metric)
Ranked #3 on
Language Modelling
on The Pile
(Test perplexity metric)
