Many-to-Many Spoken Language Translation via Unified Speech and Text Representation Learning with Unit-to-Unit Translation
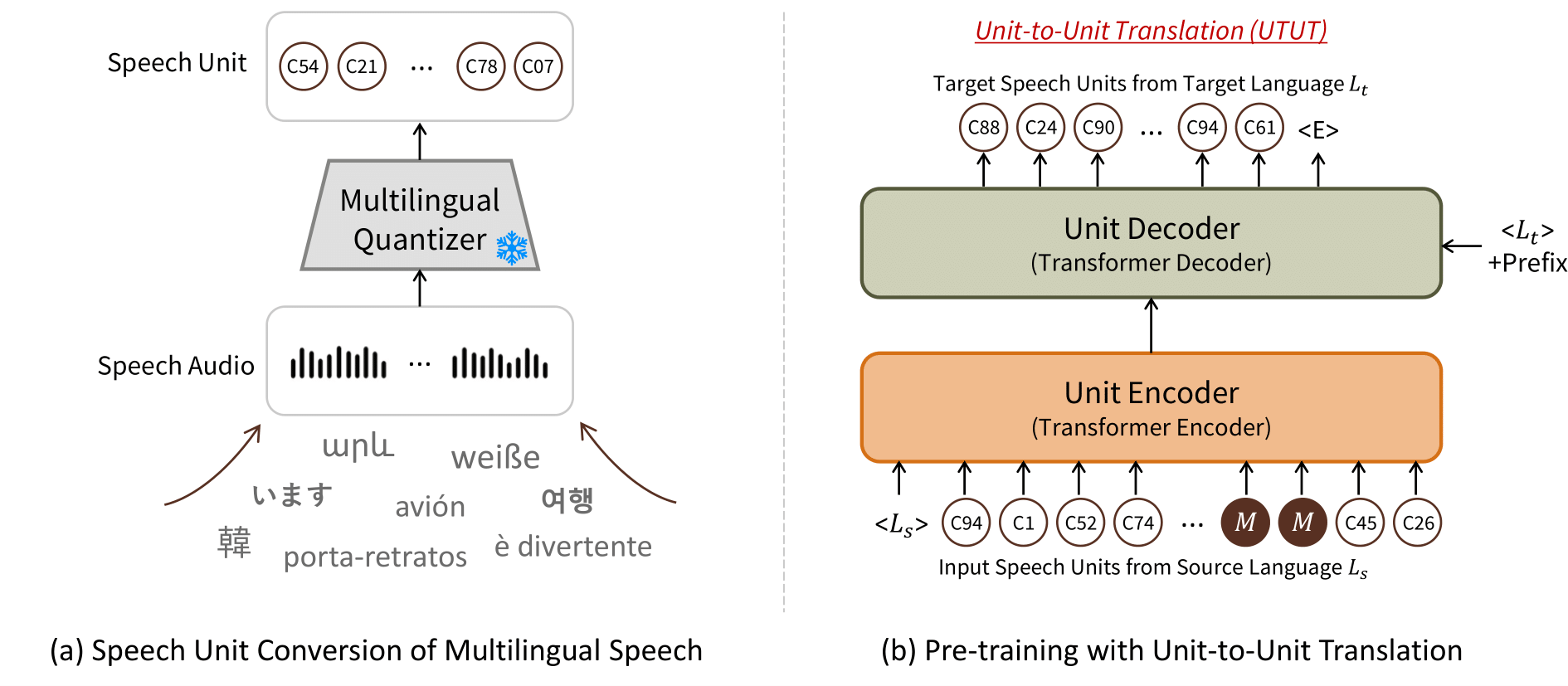
In this paper, we propose a method to learn unified representations of multilingual speech and text with a single model, especially focusing on the purpose of speech synthesis. We represent multilingual speech audio with speech units, the quantized representations of speech features encoded from a self-supervised speech model. Therefore, we can focus on their linguistic content by treating the audio as pseudo text and can build a unified representation of speech and text. Then, we propose to train an encoder-decoder structured model with a Unit-to-Unit Translation (UTUT) objective on multilingual data. Specifically, by conditioning the encoder with the source language token and the decoder with the target language token, the model is optimized to translate the spoken language into that of the target language, in a many-to-many language translation setting. Therefore, the model can build the knowledge of how spoken languages are comprehended and how to relate them to different languages. A single pre-trained model with UTUT can be employed for diverse multilingual speech- and text-related tasks, such as Speech-to-Speech Translation (STS), multilingual Text-to-Speech Synthesis (TTS), and Text-to-Speech Translation (TTST). By conducting comprehensive experiments encompassing various languages, we validate the efficacy of the proposed method across diverse multilingual tasks. Moreover, we show UTUT can perform many-to-many language STS, which has not been previously explored in the literature. Samples are available on https://choijeongsoo.github.io/utut.
PDF Abstract



