Predictive Coding Based Multiscale Network with Encoder-Decoder LSTM for Video Prediction
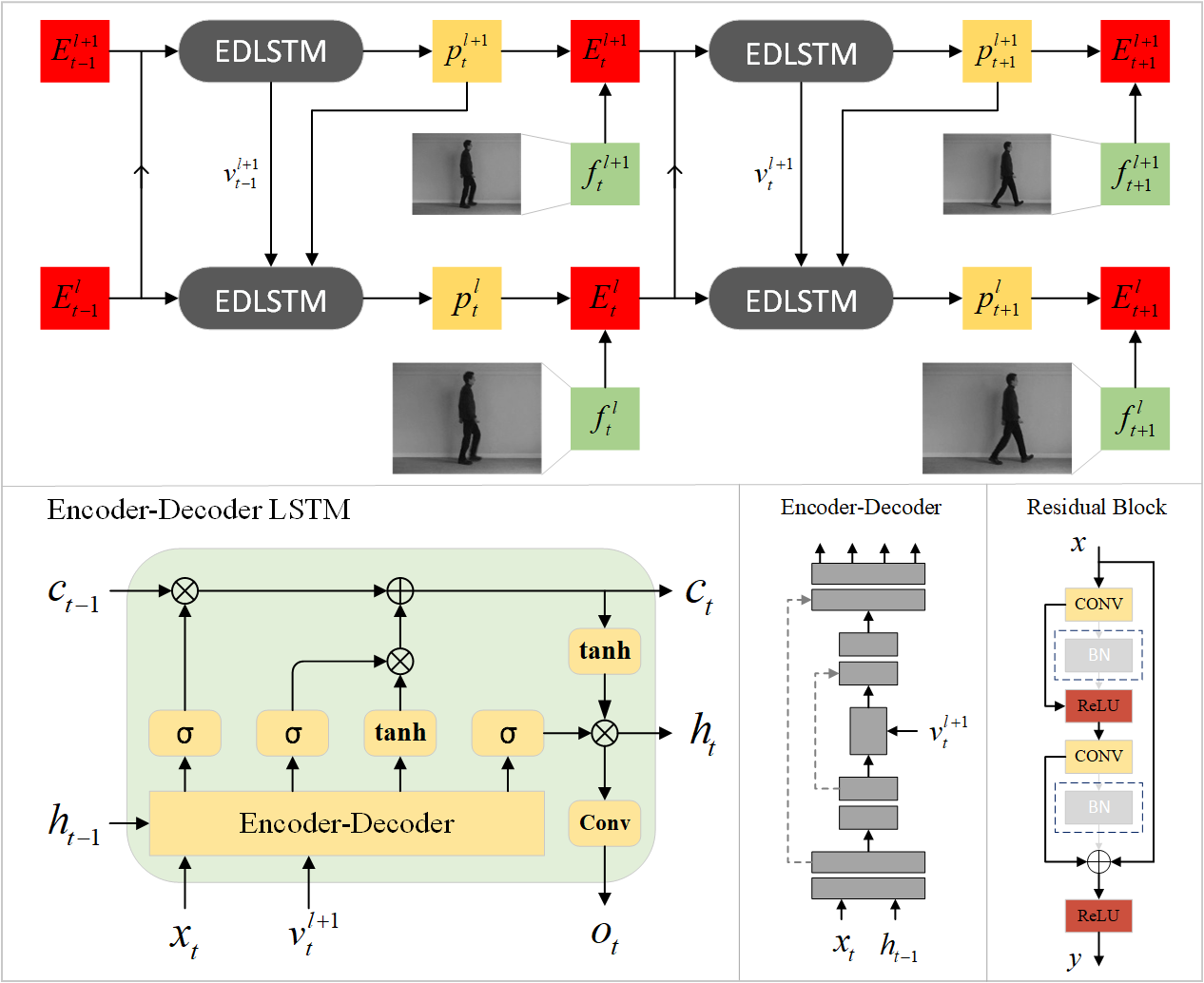
We present a multi-scale predictive coding model for future video frames prediction. Drawing inspiration on the ``Predictive Coding" theories in cognitive science, it is updated by a combination of bottom-up and top-down information flows, which can enhance the interaction between different network levels. However, traditional predictive coding models only predict what is happening hierarchically rather than predicting the future. To address the problem, our model employs a multi-scale approach (Coarse to Fine), where the higher level neurons generate coarser predictions (lower resolution), while the lower level generate finer predictions (higher resolution). In terms of network architecture, we directly incorporate the encoder-decoder network within the LSTM module and share the final encoded high-level semantic information across different network levels. This enables comprehensive interaction between the current input and the historical states of LSTM compared with the traditional Encoder-LSTM-Decoder architecture, thus learning more believable temporal and spatial dependencies. Furthermore, to tackle the instability in adversarial training and mitigate the accumulation of prediction errors in long-term prediction, we propose several improvements to the training strategy. Our approach achieves good performance on datasets such as KTH, Moving MNIST and Caltech Pedestrian. Code is available at https://github.com/Ling-CF/MSPN.
PDF Abstract


 KTH
KTH
 Moving MNIST
Moving MNIST
