PSLA: Improving Audio Tagging with Pretraining, Sampling, Labeling, and Aggregation
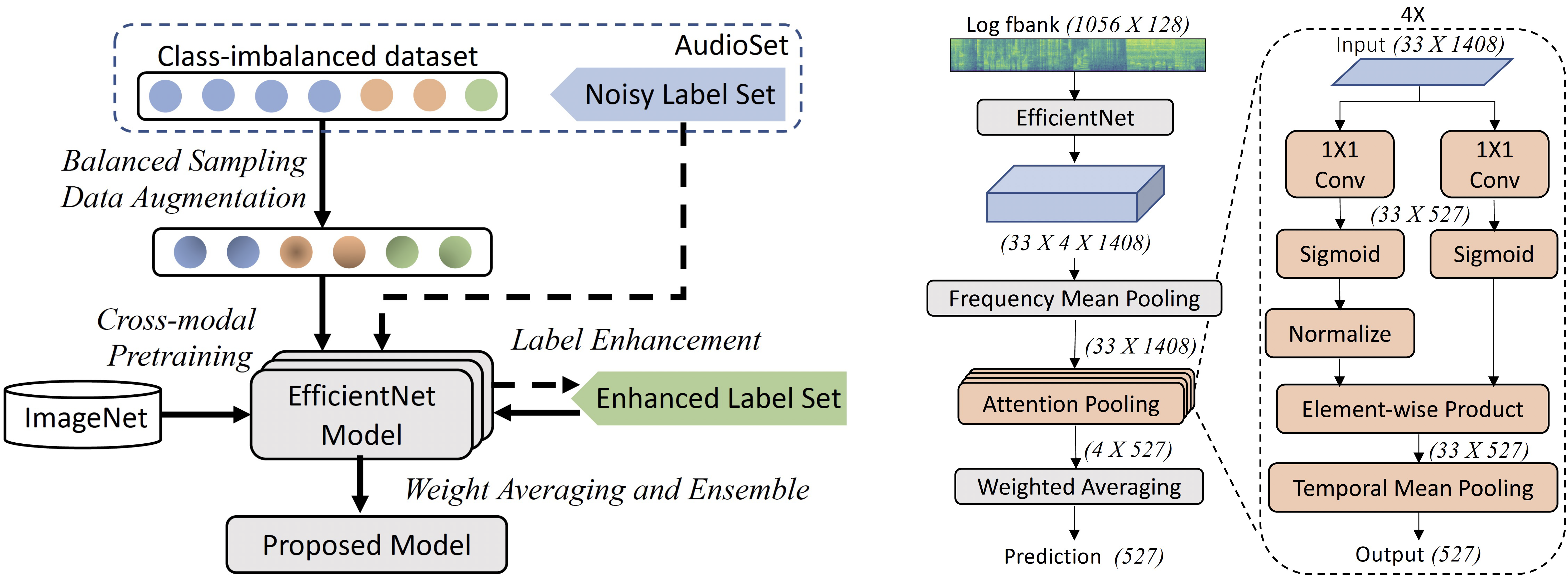
Audio tagging is an active research area and has a wide range of applications. Since the release of AudioSet, great progress has been made in advancing model performance, which mostly comes from the development of novel model architectures and attention modules. However, we find that appropriate training techniques are equally important for building audio tagging models with AudioSet, but have not received the attention they deserve. To fill the gap, in this work, we present PSLA, a collection of training techniques that can noticeably boost the model accuracy including ImageNet pretraining, balanced sampling, data augmentation, label enhancement, model aggregation and their design choices. By training an EfficientNet with these techniques, we obtain a single model (with 13.6M parameters) and an ensemble model that achieve mean average precision (mAP) scores of 0.444 and 0.474 on AudioSet, respectively, outperforming the previous best system of 0.439 with 81M parameters. In addition, our model also achieves a new state-of-the-art mAP of 0.567 on FSD50K.
PDF AbstractCode
 Colab
Colab




 AudioSet
AudioSet
 FSD50K
FSD50K
Results from the Paper
 Ranked #6 on
Audio Classification
on FSD50K
(using extra training data)
Ranked #6 on
Audio Classification
on FSD50K
(using extra training data)
