Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers
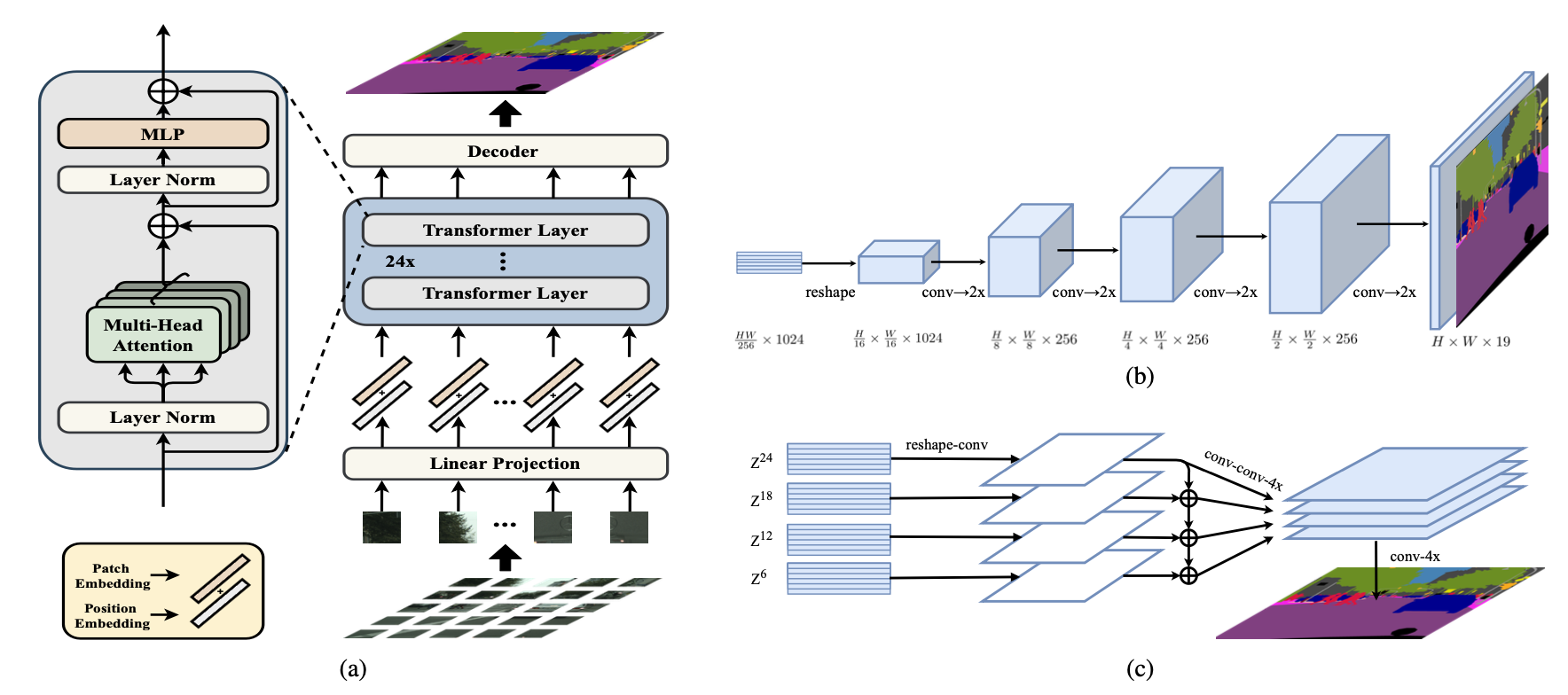
Most recent semantic segmentation methods adopt a fully-convolutional network (FCN) with an encoder-decoder architecture. The encoder progressively reduces the spatial resolution and learns more abstract/semantic visual concepts with larger receptive fields. Since context modeling is critical for segmentation, the latest efforts have been focused on increasing the receptive field, through either dilated/atrous convolutions or inserting attention modules. However, the encoder-decoder based FCN architecture remains unchanged. In this paper, we aim to provide an alternative perspective by treating semantic segmentation as a sequence-to-sequence prediction task. Specifically, we deploy a pure transformer (ie, without convolution and resolution reduction) to encode an image as a sequence of patches. With the global context modeled in every layer of the transformer, this encoder can be combined with a simple decoder to provide a powerful segmentation model, termed SEgmentation TRansformer (SETR). Extensive experiments show that SETR achieves new state of the art on ADE20K (50.28% mIoU), Pascal Context (55.83% mIoU) and competitive results on Cityscapes. Particularly, we achieve the first position in the highly competitive ADE20K test server leaderboard on the day of submission.
PDF Abstract CVPR 2021 PDF CVPR 2021 AbstractCode





 Cityscapes
Cityscapes
 ADE20K
ADE20K
 PASCAL Context
PASCAL Context
 DensePASS
DensePASS
 DADA-seg
DADA-seg
 MICCAI 2015 Multi-Atlas Abdomen Labeling Challenge
MICCAI 2015 Multi-Atlas Abdomen Labeling Challenge
 FoodSeg103
FoodSeg103
Results from the Paper
 Ranked #2 on
Semantic Segmentation
on FoodSeg103
(using extra training data)
Ranked #2 on
Semantic Segmentation
on FoodSeg103
(using extra training data)
