Revisiting Pre-training in Audio-Visual Learning
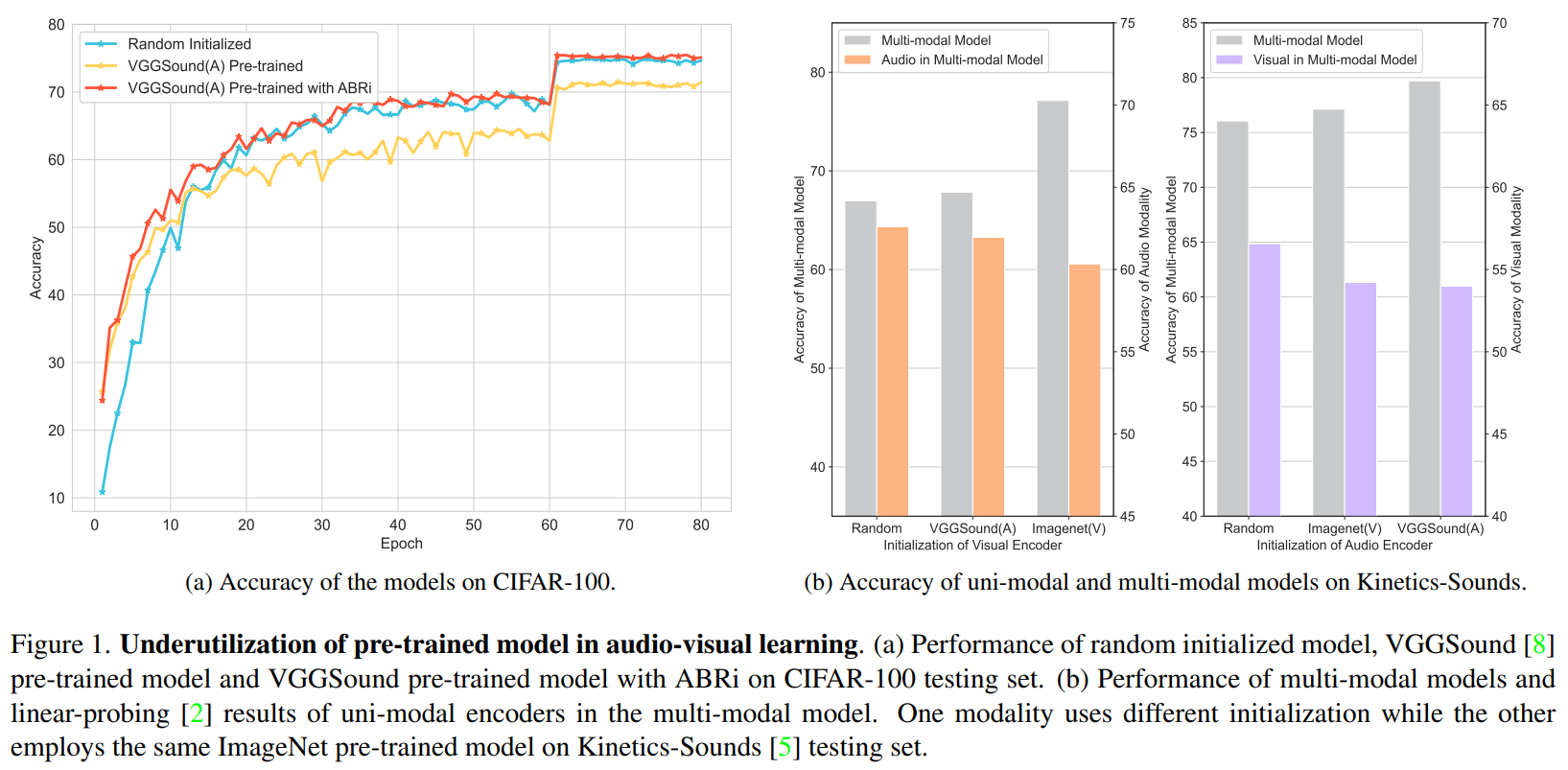
Pre-training technique has gained tremendous success in enhancing model performance on various tasks, but found to perform worse than training from scratch in some uni-modal situations. This inspires us to think: are the pre-trained models always effective in the more complex multi-modal scenario, especially for the heterogeneous modalities such as audio and visual ones? We find that the answer is No. Specifically, we explore the effects of pre-trained models on two audio-visual learning scenarios: cross-modal initialization and multi-modal joint learning. When cross-modal initialization is applied, the phenomena of "dead channel" caused by abnormal Batchnorm parameters hinders the utilization of model capacity. Thus, we propose Adaptive Batchnorm Re-initialization (ABRi) to better exploit the capacity of pre-trained models for target tasks. In multi-modal joint learning, we find a strong pre-trained uni-modal encoder would bring negative effects on the encoder of another modality. To alleviate such problem, we introduce a two-stage Fusion Tuning strategy, taking better advantage of the pre-trained knowledge while making the uni-modal encoders cooperate with an adaptive masking method. The experiment results show that our methods could further exploit pre-trained models' potential and boost performance in audio-visual learning.
PDF Abstract

 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 UCF101
UCF101
 Caltech-256
Caltech-256
 ESC-50
ESC-50
 VGG-Sound
VGG-Sound
