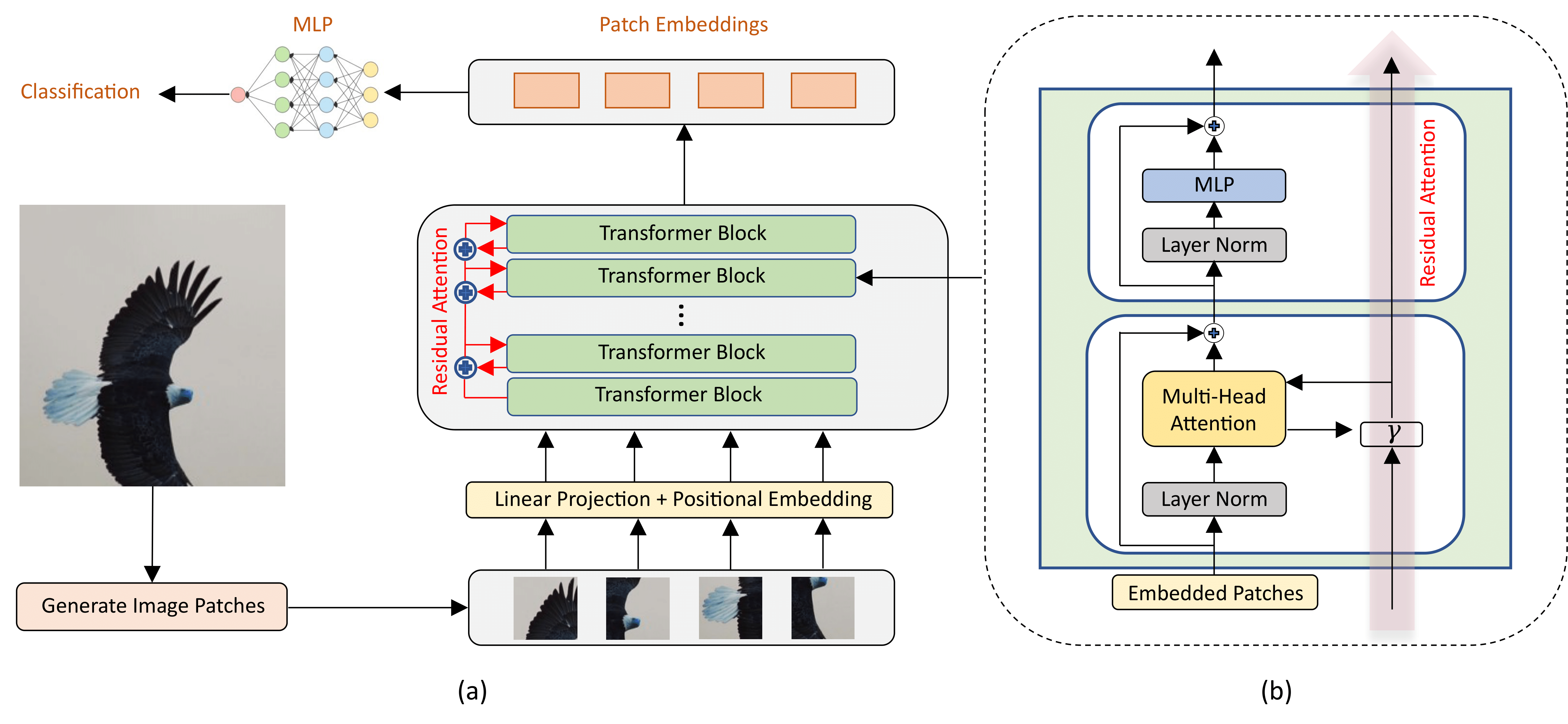
ReViT: Enhancing Vision Transformers with Attention Residual Connections for Visual Recognition
Vision Transformer (ViT) self-attention mechanism is characterized by feature collapse in deeper layers, resulting in the vanishing of low-level visual features. However, such features can be helpful to accurately represent and identify elements within an image and increase the accuracy and robustness of vision-based recognition systems. Following this rationale, we propose a novel residual attention learning method for improving ViT-based architectures, increasing their visual feature diversity and model robustness. In this way, the proposed network can capture and preserve significant low-level features, providing more details about the elements within the scene being analyzed. The effectiveness and robustness of the presented method are evaluated on five image classification benchmarks, including ImageNet1k, CIFAR10, CIFAR100, Oxford Flowers-102, and Oxford-IIIT Pet, achieving improved performances. Additionally, experiments on the COCO2017 dataset show that the devised approach discovers and incorporates semantic and spatial relationships for object detection and instance segmentation when implemented into spatial-aware transformer models.
PDF AbstractCode






 CIFAR-10
CIFAR-10
 ImageNet
ImageNet
 MS COCO
MS COCO
 CIFAR-100
CIFAR-100
 Oxford 102 Flower
Oxford 102 Flower
 Oxford-IIIT Pet Dataset
Oxford-IIIT Pet Dataset

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Image Classification | ImageNet | ReViT-B | Top 1 Accuracy | 82.4 | # 492 |
