Riemannian Preconditioned LoRA for Fine-Tuning Foundation Models
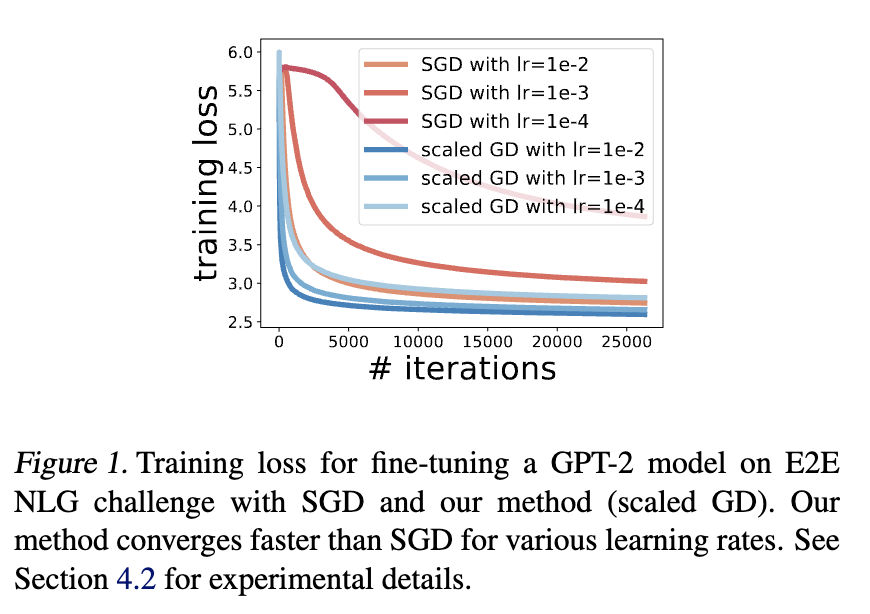
In this work we study the enhancement of Low Rank Adaptation (LoRA) fine-tuning procedure by introducing a Riemannian preconditioner in its optimization step. Specifically, we introduce an $r\times r$ preconditioner in each gradient step where $r$ is the LoRA rank. This preconditioner requires a small change to existing optimizer code and creates virtually minuscule storage and runtime overhead. Our experimental results with both large language models and text-to-image diffusion models show that with our preconditioner, the convergence and reliability of SGD and AdamW can be significantly enhanced. Moreover, the training process becomes much more robust to hyperparameter choices such as learning rate. Theoretically, we show that fine-tuning a two-layer ReLU network in the convex paramaterization with our preconditioner has convergence rate independent of condition number of the data matrix. This new Riemannian preconditioner, previously explored in classic low-rank matrix recovery, is introduced to deep learning tasks for the first time in our work. We release our code at https://github.com/pilancilab/Riemannian_Preconditioned_LoRA.
PDF Abstract
 GLUE
GLUE
