Semantify: Simplifying the Control of 3D Morphable Models using CLIP
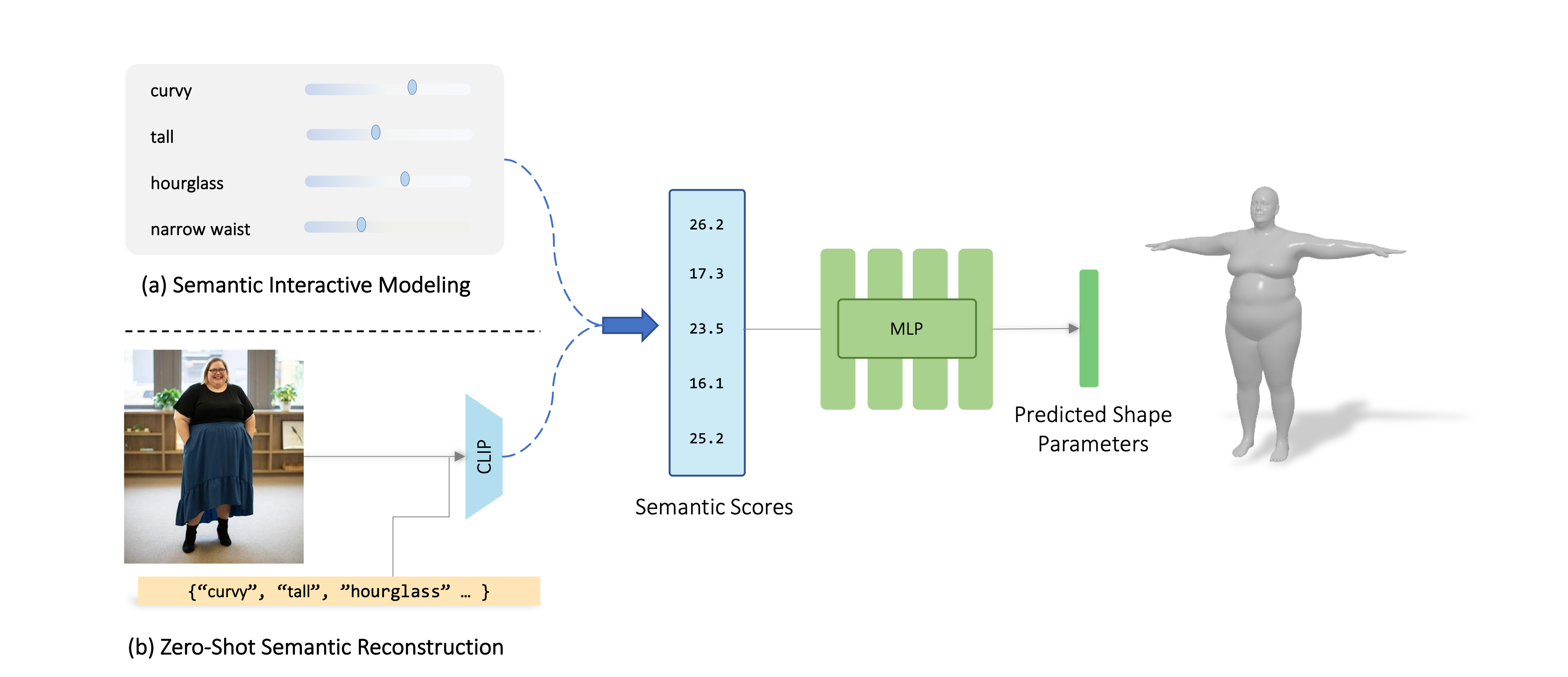
We present Semantify: a self-supervised method that utilizes the semantic power of CLIP language-vision foundation model to simplify the control of 3D morphable models. Given a parametric model, training data is created by randomly sampling the model's parameters, creating various shapes and rendering them. The similarity between the output images and a set of word descriptors is calculated in CLIP's latent space. Our key idea is first to choose a small set of semantically meaningful and disentangled descriptors that characterize the 3DMM, and then learn a non-linear mapping from scores across this set to the parametric coefficients of the given 3DMM. The non-linear mapping is defined by training a neural network without a human-in-the-loop. We present results on numerous 3DMMs: body shape models, face shape and expression models, as well as animal shapes. We demonstrate how our method defines a simple slider interface for intuitive modeling, and show how the mapping can be used to instantly fit a 3D parametric body shape to in-the-wild images.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract
 HBW
HBW
