ViDeNN: Deep Blind Video Denoising
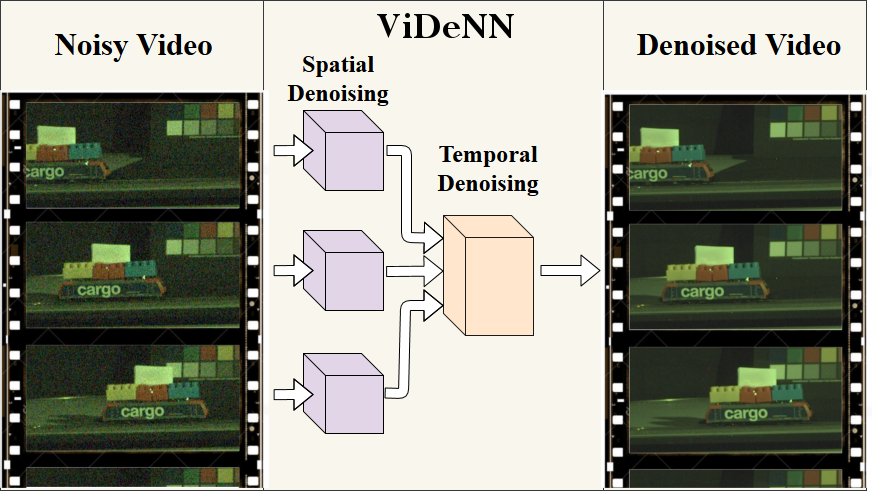
We propose ViDeNN: a CNN for Video Denoising without prior knowledge on the noise distribution (blind denoising). The CNN architecture uses a combination of spatial and temporal filtering, learning to spatially denoise the frames first and at the same time how to combine their temporal information, handling objects motion, brightness changes, low-light conditions and temporal inconsistencies. We demonstrate the importance of the data used for CNNs training, creating for this purpose a specific dataset for low-light conditions. We test ViDeNN on common benchmarks and on self-collected data, achieving good results comparable with the state-of-the-art.
PDF AbstractCode

Tasks


 RENOIR
RENOIR

Methods
No methods listed for this paper. Add
relevant methods here
