Search Results for author:
Found 172 papers, 58 papers with code
How Good is my Video LMM? Complex Video Reasoning and Robustness Evaluation Suite for Video-LMMs
Recent advancements in Large Language Models (LLMs) have led to the development of Video Large Multi-modal Models (Video-LMMs) that can handle a wide range of video understanding tasks.

EchoScene: Indoor Scene Generation via Information Echo over Scene Graph Diffusion
The scheme ensures that the denoising processes are influenced by a holistic understanding of the scene graph, facilitating the generation of globally coherent scenes.


BRAVE: Broadening the visual encoding of vision-language models
Our results highlight the potential of incorporating different visual biases for a more broad and contextualized visual understanding of VLMs.

PhysAvatar: Learning the Physics of Dressed 3D Avatars from Visual Observations
This marks a significant advancement towards modeling photorealistic digital humans using physically based inverse rendering with physics in the loop.
OpenNeRF: Open Set 3D Neural Scene Segmentation with Pixel-Wise Features and Rendered Novel Views
Our OpenNeRF further leverages NeRF's ability to render novel views and extract open-set VLM features from areas that are not well observed in the initial posed images.
Know Your Neighbors: Improving Single-View Reconstruction via Spatial Vision-Language Reasoning
We propose KYN, a novel method for single-view scene reconstruction that reasons about semantic and spatial context to predict each point's density.


3D scene generation from scene graphs and self-attention
Synthesizing realistic and diverse indoor 3D scene layouts in a controllable fashion opens up applications in simulated navigation and virtual reality.
Few-shot point cloud reconstruction and denoising via learned Guassian splats renderings and fine-tuned diffusion features
Existing deep learning methods for the reconstruction and denoising of point clouds rely on small datasets of 3D shapes.
CLoRA: A Contrastive Approach to Compose Multiple LoRA Models
Low-Rank Adaptations (LoRAs) have emerged as a powerful and popular technique in the field of image generation, offering a highly effective way to adapt and refine pre-trained deep learning models for specific tasks without the need for comprehensive retraining.

Zero123-6D: Zero-shot Novel View Synthesis for RGB Category-level 6D Pose Estimation
Estimating the pose of objects through vision is essential to make robotic platforms interact with the environment.


RadSplat: Radiance Field-Informed Gaussian Splatting for Robust Real-Time Rendering with 900+ FPS
First, we use radiance fields as a prior and supervision signal for optimizing point-based scene representations, leading to improved quality and more robust optimization.
GeoGaussian: Geometry-aware Gaussian Splatting for Scene Rendering
During the Gaussian Splatting optimization process, the scene's geometry can gradually deteriorate if its structure is not deliberately preserved, especially in non-textured regions such as walls, ceilings, and furniture surfaces.
KP-RED: Exploiting Semantic Keypoints for Joint 3D Shape Retrieval and Deformation
In this paper, we present KP-RED, a unified KeyPoint-driven REtrieval and Deformation framework that takes object scans as input and jointly retrieves and deforms the most geometrically similar CAD models from a pre-processed database to tightly match the target.
FocusCLIP: Multimodal Subject-Level Guidance for Zero-Shot Transfer in Human-Centric Tasks
We propose FocusCLIP, integrating subject-level guidance--a specialized mechanism for target-specific supervision--into the CLIP framework for improved zero-shot transfer on human-centric tasks.
 Ranked #1 on
Emotion Recognition
on EMOTIC
Ranked #1 on
Emotion Recognition
on EMOTIC
HyperSDFusion: Bridging Hierarchical Structures in Language and Geometry for Enhanced 3D Text2Shape Generation
Since hyperbolic space is suitable for handling hierarchical data, we propose to learn the hierarchical representations of text and 3D shapes in hyperbolic space.


OpenSUN3D: 1st Workshop Challenge on Open-Vocabulary 3D Scene Understanding
This report provides an overview of the challenge hosted at the OpenSUN3D Workshop on Open-Vocabulary 3D Scene Understanding held in conjunction with ICCV 2023.
Physics-Encoded Graph Neural Networks for Deformation Prediction under Contact
We also incorporate cross-attention mechanisms to capture the interplay between the objects.
Denoising Diffusion via Image-Based Rendering
In this work, we introduce the first diffusion model able to perform fast, detailed reconstruction and generation of real-world 3D scenes.

InseRF: Text-Driven Generative Object Insertion in Neural 3D Scenes
We introduce InseRF, a novel method for generative object insertion in the NeRF reconstructions of 3D scenes.

Learning to Prompt with Text Only Supervision for Vision-Language Models
While effective, most of these works require labeled data which is not practical, and often struggle to generalize towards new datasets due to over-fitting on the source data.

Segment3D: Learning Fine-Grained Class-Agnostic 3D Segmentation without Manual Labels
Therefore, we explore the use of image segmentation foundation models to automatically generate training labels for 3D segmentation.

UniSDF: Unifying Neural Representations for High-Fidelity 3D Reconstruction of Complex Scenes with Reflections
In this work, we propose UniSDF, a general purpose 3D reconstruction method that can reconstruct large complex scenes with reflections.
Text-Conditioned Resampler For Long Form Video Understanding
In this paper we present a text-conditioned video resampler (TCR) module that uses a pre-trained and frozen visual encoder and large language model (LLM) to process long video sequences for a task.
 Ranked #5 on
Video Question Answering
on NExT-QA
Ranked #5 on
Video Question Answering
on NExT-QA
LIME: Localized Image Editing via Attention Regularization in Diffusion Models
Diffusion models (DMs) have gained prominence due to their ability to generate high-quality, varied images, with recent advancements in text-to-image generation.
CONFORM: Contrast is All You Need For High-Fidelity Text-to-Image Diffusion Models
Images produced by text-to-image diffusion models might not always faithfully represent the semantic intent of the provided text prompt, where the model might overlook or entirely fail to produce certain objects.
Re-Nerfing: Improving Novel Views Synthesis through Novel Views Synthesis
With Re-Nerfing, we enhance the geometric consistency of novel views as follows: First, we train a NeRF with the available views.

DNS SLAM: Dense Neural Semantic-Informed SLAM
In this work, we introduce DNS SLAM, a novel neural RGB-D semantic SLAM approach featuring a hybrid representation.

SemiVL: Semi-Supervised Semantic Segmentation with Vision-Language Guidance
In SemiVL, we propose to integrate rich priors from VLM pre-training into semi-supervised semantic segmentation to learn better semantic decision boundaries.
 Ranked #1 on
Semi-Supervised Semantic Segmentation
on PASCAL VOC 2012 732 labeled
(using extra training data)
Ranked #1 on
Semi-Supervised Semantic Segmentation
on PASCAL VOC 2012 732 labeled
(using extra training data)
D-SCo: Dual-Stream Conditional Diffusion for Monocular Hand-Held Object Reconstruction
Second, we introduce a dual-stream denoiser to semantically and geometrically model hand-object interactions with a novel unified hand-object semantic embedding, enhancing the reconstruction performance of the hand-occluded region of the object.
3D Compression Using Neural Fields
Neural Fields (NFs) have gained momentum as a tool for compressing various data modalities - e. g. images and videos.
SecondPose: SE(3)-Consistent Dual-Stream Feature Fusion for Category-Level Pose Estimation
Leveraging the advantage of DINOv2 in providing SE(3)-consistent semantic features, we hierarchically extract two types of SE(3)-invariant geometric features to further encapsulate local-to-global object-specific information.

SILC: Improving Vision Language Pretraining with Self-Distillation
However, the contrastive objective used by these models only focuses on image-text alignment and does not incentivise image feature learning for dense prediction tasks.



MOHO: Learning Single-view Hand-held Object Reconstruction with Multi-view Occlusion-Aware Supervision
Previous works concerning single-view hand-held object reconstruction typically rely on supervision from 3D ground-truth models, which are hard to collect in real world.
SG-Bot: Object Rearrangement via Coarse-to-Fine Robotic Imagination on Scene Graphs
In this paper, we present SG-Bot, a novel rearrangement framework that utilizes a coarse-to-fine scheme with a scene graph as the scene representation.
Dynamic Hyperbolic Attention Network for Fine Hand-object Reconstruction
In this work, we propose the first precise hand-object reconstruction method in hyperbolic space, namely Dynamic Hyperbolic Attention Network (DHANet), which leverages intrinsic properties of hyperbolic space to learn representative features.
Introducing Language Guidance in Prompt-based Continual Learning
While the model faces a disjoint set of classes in each task in this setting, we argue that these classes can be encoded to the same embedding space of a pre-trained language encoder.

3D Adversarial Augmentations for Robust Out-of-Domain Predictions
We conduct extensive experiments across a variety of scenarios on data from KITTI, Waymo, and CrashD for 3D object detection, and on data from SemanticKITTI, Waymo, and nuScenes for 3D semantic segmentation.


Robust Monocular Depth Estimation under Challenging Conditions
While state-of-the-art monocular depth estimation approaches achieve impressive results in ideal settings, they are highly unreliable under challenging illumination and weather conditions, such as at nighttime or in the presence of rain.
CCD-3DR: Consistent Conditioning in Diffusion for Single-Image 3D Reconstruction
However, such strategies fail to consistently align the denoised point cloud with the given image, leading to unstable conditioning and inferior performance.
U-RED: Unsupervised 3D Shape Retrieval and Deformation for Partial Point Clouds
In this paper, we propose U-RED, an Unsupervised shape REtrieval and Deformation pipeline that takes an arbitrary object observation as input, typically captured by RGB images or scans, and jointly retrieves and deforms the geometrically similar CAD models from a pre-established database to tightly match the target.
View-to-Label: Multi-View Consistency for Self-Supervised 3D Object Detection
For autonomous vehicles, driving safely is highly dependent on the capability to correctly perceive the environment in 3D space, hence the task of 3D object detection represents a fundamental aspect of perception.
CommonScenes: Generating Commonsense 3D Indoor Scenes with Scene Graph Diffusion
The generated scenes can be manipulated by editing the input scene graph and sampling the noise in the diffusion model.
Incremental 3D Semantic Scene Graph Prediction from RGB Sequences
Our method consists of a novel incremental entity estimation pipeline and a scene graph prediction network.
SparseFusion: Fusing Multi-Modal Sparse Representations for Multi-Sensor 3D Object Detection
However, given that objects occupy only a small part of a scene, finding dense candidates and generating dense representations is noisy and inefficient.
TextMesh: Generation of Realistic 3D Meshes From Text Prompts
In addition, we propose a novel way to finetune the mesh texture, removing the effect of high saturation and improving the details of the output 3D mesh.
NEWTON: Neural View-Centric Mapping for On-the-Fly Large-Scale SLAM
However, in real-time and on-the-fly scene capture applications, this prior knowledge cannot be assumed as fixed or static, since it dynamically changes and it is subject to significant updates based on run-time observations.
NeRFMeshing: Distilling Neural Radiance Fields into Geometrically-Accurate 3D Meshes
Obtaining 3D meshes from neural radiance fields still remains an open challenge since NeRFs are optimized for view synthesis, not enforcing an accurate underlying geometry on the radiance field.
Unsupervised Traffic Scene Generation with Synthetic 3D Scene Graphs
Image synthesis driven by computer graphics achieved recently a remarkable realism, yet synthetic image data generated this way reveals a significant domain gap with respect to real-world data.

IPCC-TP: Utilizing Incremental Pearson Correlation Coefficient for Joint Multi-Agent Trajectory Prediction
Reliable multi-agent trajectory prediction is crucial for the safe planning and control of autonomous systems.
SupeRGB-D: Zero-shot Instance Segmentation in Cluttered Indoor Environments
We introduce a zero-shot split for Tabletop Objects Dataset (TOD-Z) to enable this study and present a method that uses annotated objects to learn the ``objectness'' of pixels and generalize to unseen object categories in cluttered indoor environments.

SST: Real-time End-to-end Monocular 3D Reconstruction via Sparse Spatial-Temporal Guidance
Real-time monocular 3D reconstruction is a challenging problem that remains unsolved.
I2MVFormer: Large Language Model Generated Multi-View Document Supervision for Zero-Shot Image Classification
Our proposed model, I2MVFormer, learns multi-view semantic embeddings for zero-shot image classification with these class views.

LatentSwap3D: Semantic Edits on 3D Image GANs
3D GANs have the ability to generate latent codes for entire 3D volumes rather than only 2D images.
Shape, Pose, and Appearance from a Single Image via Bootstrapped Radiance Field Inversion
Neural Radiance Fields (NeRF) coupled with GANs represent a promising direction in the area of 3D reconstruction from a single view, owing to their ability to efficiently model arbitrary topologies.
SPARF: Neural Radiance Fields from Sparse and Noisy Poses
Neural Radiance Field (NeRF) has recently emerged as a powerful representation to synthesize photorealistic novel views.
DisPositioNet: Disentangled Pose and Identity in Semantic Image Manipulation
Graph representation of objects and their relations in a scene, known as a scene graph, provides a precise and discernible interface to manipulate a scene by modifying the nodes or the edges in the graph.
ParGAN: Learning Real Parametrizable Transformations
Current methods for image-to-image translation produce compelling results, however, the applied transformation is difficult to control, since existing mechanisms are often limited and non-intuitive.

OPA-3D: Occlusion-Aware Pixel-Wise Aggregation for Monocular 3D Object Detection
Despite monocular 3D object detection having recently made a significant leap forward thanks to the use of pre-trained depth estimators for pseudo-LiDAR recovery, such two-stage methods typically suffer from overfitting and are incapable of explicitly encapsulating the geometric relation between depth and object bounding box.
MonoGraspNet: 6-DoF Grasping with a Single RGB Image
6-DoF robotic grasping is a long-lasting but unsolved problem.
I2DFormer: Learning Image to Document Attention for Zero-Shot Image Classification
In order to distill discriminative visual words from noisy documents, we introduce a new cross-modal attention module that learns fine-grained interactions between image patches and document words.
Query-Guided Networks for Few-shot Fine-grained Classification and Person Search
Few-shot fine-grained classification and person search appear as distinct tasks and literature has treated them separately.

Segmenting Known Objects and Unseen Unknowns without Prior Knowledge
By doing so, for the first time in panoptic segmentation with unknown objects, our U3HS is trained without unknown categories, reducing assumptions and leaving the settings as unconstrained as in real-life scenarios.

ManiFlow: Implicitly Representing Manifolds with Normalizing Flows
In contrast to prior work, we approach this problem by generating samples from the original data distribution given full knowledge about the perturbed distribution and the noise model.
SC-Explorer: Incremental 3D Scene Completion for Safe and Efficient Exploration Mapping and Planning
We further present an informative path planning method, leveraging the capabilities of our mapping approach and a novel scene-completion-aware information gain.
SSP-Pose: Symmetry-Aware Shape Prior Deformation for Direct Category-Level Object Pose Estimation
In this paper, to handle these shortcomings, we propose an end-to-end trainable network SSP-Pose for category-level pose estimation, which integrates shape priors into a direct pose regression network.
CloudAttention: Efficient Multi-Scale Attention Scheme For 3D Point Cloud Learning
The proposed hierarchical model achieves state-of-the-art shape classification in mean accuracy and yields results on par with the previous segmentation methods while requiring significantly fewer computations.
RBP-Pose: Residual Bounding Box Projection for Category-Level Pose Estimation
Category-level object pose estimation aims to predict the 6D pose as well as the 3D metric size of arbitrary objects from a known set of categories.
GOCA: Guided Online Cluster Assignment for Self-Supervised Video Representation Learning
Specifically, we outperform the state of the art by 7% on UCF and 4% on HMDB for video retrieval, and 5% on UCF and 6% on HMDB for video classification


E-Graph: Minimal Solution for Rigid Rotation with Extensibility Graphs
Minimal solutions for relative rotation and translation estimation tasks have been explored in different scenarios, typically relying on the so-called co-visibility graph.
SHIFT: A Synthetic Driving Dataset for Continuous Multi-Task Domain Adaptation
Adapting to a continuously evolving environment is a safety-critical challenge inevitably faced by all autonomous driving systems.

SoftPool++: An Encoder-Decoder Network for Point Cloud Completion
We propose a novel convolutional operator for the task of point cloud completion.
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
Large pretrained (e. g., "foundation") models exhibit distinct capabilities depending on the domain of data they are trained on.
 Ranked #21 on
Video Retrieval
on MSR-VTT-1kA
(video-to-text R@1 metric)
Ranked #21 on
Video Retrieval
on MSR-VTT-1kA
(video-to-text R@1 metric)

Learning Local Displacements for Point Cloud Completion
To this aim, we introduce a second model that assembles our layers within a transformer architecture.
4D-OR: Semantic Scene Graphs for OR Domain Modeling
Towards this goal, for the first time, we propose using semantic scene graphs (SSG) to describe and summarize the surgical scene.
 Ranked #4 on
Scene Graph Generation
on 4D-OR
Ranked #4 on
Scene Graph Generation
on 4D-OR
Occlusion-Aware Self-Supervised Monocular 6D Object Pose Estimation
6D object pose estimation is a fundamental yet challenging problem in computer vision.

ZebraPose: Coarse to Fine Surface Encoding for 6DoF Object Pose Estimation
Dense methods also improved pose estimation in the presence of occlusion.
GPV-Pose: Category-level Object Pose Estimation via Geometry-guided Point-wise Voting
While 6D object pose estimation has recently made a huge leap forward, most methods can still only handle a single or a handful of different objects, which limits their applications.
 Ranked #1 on
6D Pose Estimation
on LineMOD
(Mean ADD-S metric)
Ranked #1 on
6D Pose Estimation
on LineMOD
(Mean ADD-S metric)
From 2D to 3D: Re-thinking Benchmarking of Monocular Depth Prediction
There have been numerous recently proposed methods for monocular depth prediction (MDP) coupled with the equally rapid evolution of benchmarking tools.
Time-to-Label: Temporal Consistency for Self-Supervised Monocular 3D Object Detection
Monocular 3D object detection continues to attract attention due to the cost benefits and wider availability of RGB cameras.
Bending Graphs: Hierarchical Shape Matching using Gated Optimal Transport
Shape matching has been a long-studied problem for the computer graphics and vision community.
Transformers in Action: Weakly Supervised Action Segmentation
The video action segmentation task is regularly explored under weaker forms of supervision, such as transcript supervision, where a list of actions is easier to obtain than dense frame-wise labels.
3D-VField: Adversarial Augmentation of Point Clouds for Domain Generalization in 3D Object Detection
Despite training only on a standard dataset, such as KITTI, augmenting with our vector fields significantly improves the generalization to differently shaped objects and scenes.
Implicit Neural Representations for Image Compression
Recently Implicit Neural Representations (INRs) gained attention as a novel and effective representation for various data types.
Object-aware Monocular Depth Prediction with Instance Convolutions
With the advent of deep learning, estimating depth from a single RGB image has recently received a lot of attention, being capable of empowering many different applications ranging from path planning for robotics to computational cinematography.
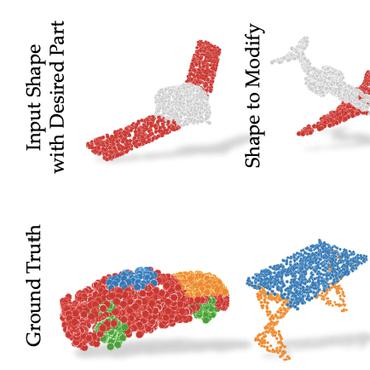
3D Compositional Zero-shot Learning with DeCompositional Consensus
Parts represent a basic unit of geometric and semantic similarity across different objects.

Neural Fields in Visual Computing and Beyond
Recent advances in machine learning have created increasing interest in solving visual computing problems using a class of coordinate-based neural networks that parametrize physical properties of scenes or objects across space and time.
Semantic Image Alignment for Vehicle Localization
Accurate and reliable localization is a fundamental requirement for autonomous vehicles to use map information in higher-level tasks such as navigation or planning.
CertainNet: Sampling-free Uncertainty Estimation for Object Detection
Estimating the uncertainty of a neural network plays a fundamental role in safety-critical settings.
Semantic Dense Reconstruction with Consistent Scene Segments
In this paper, a method for dense semantic 3D scene reconstruction from an RGB-D sequence is proposed to solve high-level scene understanding tasks.
Adversarial Domain Feature Adaptation for Bronchoscopic Depth Estimation
The results of our experiments show that the proposed method improves the network's performance on real images by a considerable margin and can be employed in 3D reconstruction pipelines.
Graph-to-3D: End-to-End Generation and Manipulation of 3D Scenes Using Scene Graphs
Scene graphs are representations of a scene, composed of objects (nodes) and inter-object relationships (edges), proven to be particularly suited for this task, as they allow for semantic control on the generated content.
SO-Pose: Exploiting Self-Occlusion for Direct 6D Pose Estimation
Directly regressing all 6 degrees-of-freedom (6DoF) for the object pose (e. g. the 3D rotation and translation) in a cluttered environment from a single RGB image is a challenging problem.
 Ranked #1 on
6D Pose Estimation using RGB
on Occlusion LineMOD
Ranked #1 on
6D Pose Estimation using RGB
on Occlusion LineMOD
Unconditional Scene Graph Generation
Scene graphs, composed of nodes as objects and directed-edges as relationships among objects, offer an alternative representation of a scene that is more semantically grounded than images.

R4Dyn: Exploring Radar for Self-Supervised Monocular Depth Estimation of Dynamic Scenes
While self-supervised monocular depth estimation in driving scenarios has achieved comparable performance to supervised approaches, violations of the static world assumption can still lead to erroneous depth predictions of traffic participants, posing a potential safety issue.
Attention-based Adversarial Appearance Learning of Augmented Pedestrians
Synthetic data became already an essential component of machine learning-based perception in the field of autonomous driving.
On the Practicality of Deterministic Epistemic Uncertainty
We find that, while DUMs scale to realistic vision tasks and perform well on OOD detection, the practicality of current methods is undermined by poor calibration under distributional shifts.
 Out of Distribution (OOD) Detection
Out of Distribution (OOD) Detection
 Semantic Segmentation
+1
Semantic Segmentation
+1
LegoFormer: Transformers for Block-by-Block Multi-view 3D Reconstruction
Most modern deep learning-based multi-view 3D reconstruction techniques use RNNs or fusion modules to combine information from multiple images after independently encoding them.
Multimodal Semantic Scene Graphs for Holistic Modeling of Surgical Procedures
We then use MSSG to introduce a dynamically generated graphical user interface tool for surgical procedure analysis which could be used for many applications including process optimization, OR design and automatic report generation.
Go with the Flows: Mixtures of Normalizing Flows for Point Cloud Generation and Reconstruction
Recently normalizing flows (NFs) have demonstrated state-of-the-art performance on modeling 3D point clouds while allowing sampling with arbitrary resolution at inference time.
KLIEP-based Density Ratio Estimation for Semantically Consistent Synthetic to Real Images Adaptation in Urban Traffic Scenes
Synthetic data has been applied in many deep learning based computer vision tasks.
SRH-Net: Stacked Recurrent Hourglass Network for Stereo Matching
The cost aggregation strategy shows a crucial role in learning-based stereo matching tasks, where 3D convolutional filters obtain state of the art but require intensive computation resources, while 2D operations need less GPU memory but are sensitive to domain shift.
Content Disentanglement for Semantically Consistent Synthetic-to-Real Domain Adaptation
Such performance drops are commonly attributed to the domain gap between real and synthetic data.
TSDF++: A Multi-Object Formulation for Dynamic Object Tracking and Reconstruction
The ability to simultaneously track and reconstruct multiple objects moving in the scene is of the utmost importance for robotic tasks such as autonomous navigation and interaction.

Variational Transformer Networks for Layout Generation
Generative models able to synthesize layouts of different kinds (e. g. documents, user interfaces or furniture arrangements) are a useful tool to aid design processes and as a first step in the generation of synthetic data, among other tasks.
ManhattanSLAM: Robust Planar Tracking and Mapping Leveraging Mixture of Manhattan Frames
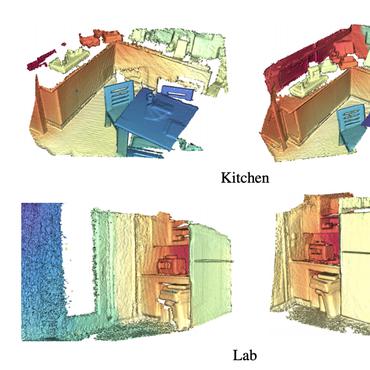
In this paper, a robust RGB-D SLAM system is proposed to utilize the structural information in indoor scenes, allowing for accurate tracking and efficient dense mapping on a CPU.
SceneGraphFusion: Incremental 3D Scene Graph Prediction from RGB-D Sequences
Scene graphs are a compact and explicit representation successfully used in a variety of 2D scene understanding tasks.
 Ranked #1 on
3D Object Classification
on 3R-Scan
Ranked #1 on
3D Object Classification
on 3R-Scan

GDR-Net: Geometry-Guided Direct Regression Network for Monocular 6D Object Pose Estimation
In this work, we perform an in-depth investigation on both direct and indirect methods, and propose a simple yet effective Geometry-guided Direct Regression Network (GDR-Net) to learn the 6D pose in an end-to-end manner from dense correspondence-based intermediate geometric representations.
Ranked #3 on
6D Pose Estimation using RGB
on Occlusion LineMOD
Unsupervised Novel View Synthesis from a Single Image
Novel view synthesis from a single image aims at generating novel views from a single input image of an object.
Learning Graph Embeddings for Compositional Zero-shot Learning
In compositional zero-shot learning, the goal is to recognize unseen compositions (e. g. old dog) of observed visual primitives states (e. g. old, cute) and objects (e. g. car, dog) in the training set.

The Hidden Uncertainty in a Neural Networks Activations
We find that this leads to improved OOD detection of epistemic uncertainty at the cost of ambiguous calibration close to the data distribution.
3DSNet: Unsupervised Shape-to-Shape 3D Style Transfer
Transferring the style from one image onto another is a popular and widely studied task in computer vision.

Batch Normalization Embeddings for Deep Domain Generalization
Several recent methods use multiple datasets to train models to extract domain-invariant features, hoping to generalize to unseen domains.
 Ranked #63 on
Domain Generalization
on PACS
Ranked #63 on
Domain Generalization
on PACS
Deep Positional and Relational Feature Learning for Rotation-Invariant Point Cloud Analysis
In this work, we propose a novel deep network for point clouds by incorporating positional information of points as inputs while yielding rotation-invariance.
A Divide et Impera Approach for 3D Shape Reconstruction from Multiple Views
Estimating the 3D shape of an object from a single or multiple images has gained popularity thanks to the recent breakthroughs powered by deep learning.

Panoster: End-to-end Panoptic Segmentation of LiDAR Point Clouds
Panoptic segmentation has recently unified semantic and instance segmentation, previously addressed separately, thus taking a step further towards creating more comprehensive and efficient perception systems.
SCFusion: Real-time Incremental Scene Reconstruction with Semantic Completion
We propose a framework that ameliorates this issue by performing scene reconstruction and semantic scene completion jointly in an incremental and real-time manner, based on an input sequence of depth maps.

Graphite: GRAPH-Induced feaTure Extraction for Point Cloud Registration
3D Point clouds are a rich source of information that enjoy growing popularity in the vision community.

RGB-D SLAM with Structural Regularities
This work proposes a RGB-D SLAM system specifically designed for structured environments and aimed at improved tracking and mapping accuracy by relying on geometric features that are extracted from the surrounding.
Robotics
SoftPoolNet: Shape Descriptor for Point Cloud Completion and Classification
In this paper, we propose a method for 3D object completion and classification based on point clouds.
Structure-SLAM: Low-Drift Monocular SLAM in Indoor Environments
In this paper a low-drift monocular SLAM method is proposed targeting indoor scenarios, where monocular SLAM often fails due to the lack of textured surfaces.
Robotics
Beyond Controlled Environments: 3D Camera Re-Localization in Changing Indoor Scenes
In this paper, we adapt 3RScan - a recently introduced indoor RGB-D dataset designed for object instance re-localization - to create RIO10, a new long-term camera re-localization benchmark focused on indoor scenes.
Binary DAD-Net: Binarized Driveable Area Detection Network for Autonomous Driving
The driveable area detection, posed as a two class segmentation task, can be efficiently modeled with slim binary networks.
Joint Detection and Tracking in Videos with Identification Features
Notably, our joint optimization maintains the detector performance, a typical multi-task challenge.

Explicit Domain Adaptation with Loosely Coupled Samples
In this work we propose a transfer learning framework, core of which is learning an explicit mapping between domains.
Self6D: Self-Supervised Monocular 6D Object Pose Estimation
6D object pose estimation is a fundamental problem in computer vision.
Learning 3D Semantic Scene Graphs from 3D Indoor Reconstructions
In our work we focus on scene graphs, a data structure that organizes the entities of a scene in a graph, where objects are nodes and their relationships modeled as edges.
 Ranked #3 on
3d scene graph generation
on 3DSSG
Ranked #3 on
3d scene graph generation
on 3DSSG
Semantic Image Manipulation Using Scene Graphs
In our work, we address the novel problem of image manipulation from scene graphs, in which a user can edit images by merely applying changes in the nodes or edges of a semantic graph that is generated from the image.

Ambiguity in Sequential Data: Predicting Uncertain Futures with Recurrent Models
Ambiguity is inherently present in many machine learning tasks, but especially for sequential models seldom accounted for, as most only output a single prediction.

Restricting the Flow: Information Bottlenecks for Attribution
Attribution methods provide insights into the decision-making of machine learning models like artificial neural networks.
Quaternion Equivariant Capsule Networks for 3D Point Clouds
We present a 3D capsule module for processing point clouds that is equivariant to 3D rotations and translations, as well as invariant to permutations of the input points.
Real-Time 3D Model Tracking in Color and Depth on a Single CPU Core
We present a novel method to track 3D models in color and depth data.
Unsupervised Monocular Depth Prediction for Indoor Continuous Video Streams
This paper studies unsupervised monocular depth prediction problem.
ForkNet: Multi-branch Volumetric Semantic Completion from a Single Depth Image
We propose a novel model for 3D semantic completion from a single depth image, based on a single encoder and three separate generators used to reconstruct different geometric and semantic representations of the original and completed scene, all sharing the same latent space.
 Ranked #7 on
3D Semantic Scene Completion
on NYUv2
(using extra training data)
Ranked #7 on
3D Semantic Scene Completion
on NYUv2
(using extra training data)
Object-Driven Multi-Layer Scene Decomposition From a Single Image
Our approach aims at building up a Layered Depth Image (LDI) from a single RGB input, which is an efficient representation that arranges the scene in layers, including originally occluded regions.
RIO: 3D Object Instance Re-Localization in Changing Indoor Environments
In this work, we introduce the task of 3D object instance re-localization (RIO): given one or multiple objects in an RGB-D scan, we want to estimate their corresponding 6DoF poses in another 3D scan of the same environment taken at a later point in time.
Grasp Type Estimation for Myoelectric Prostheses using Point Cloud Feature Learning
Prosthetic hands can help people with limb difference to return to their life routines.
Sampling-free Epistemic Uncertainty Estimation Using Approximated Variance Propagation
We present a sampling-free approach for computing the epistemic uncertainty of a neural network.
Domain-Specific Priors and Meta Learning for Few-Shot First-Person Action Recognition
The lack of large-scale real datasets with annotations makes transfer learning a necessity for video activity understanding.

Query-guided End-to-End Person Search
We extend this with i. a query-guided Siamese squeeze-and-excitation network (QSSE-Net) that uses global context from both the query and gallery images, ii.
Attention-based Lane Change Prediction
Lane change prediction of surrounding vehicles is a key building block of path planning.
3D Point Capsule Networks
In this paper, we propose 3D point-capsule networks, an auto-encoder designed to process sparse 3D point clouds while preserving spatial arrangements of the input data.
 Ranked #5 on
3D Object Classification
on ModelNet40
Ranked #5 on
3D Object Classification
on ModelNet40
Explaining the Ambiguity of Object Detection and 6D Pose From Visual Data
For each object instance we predict multiple pose and class outcomes to estimate the specific pose distribution generated by symmetries and repetitive textures.
Dealing with Ambiguity in Robotic Grasping via Multiple Predictions
Further, we reformulate the problem of robotic grasping by replacing conventional grasp rectangles with grasp belief maps, which hold more precise location information than a rectangle and account for the uncertainty inherent to the task.
Adversarial Semantic Scene Completion from a Single Depth Image
We propose a method to reconstruct, complete and semantically label a 3D scene from a single input depth image.
A Summary of the 4th International Workshop on Recovering 6D Object Pose
The workshop featured four invited talks, oral and poster presentations of accepted workshop papers, and an introduction of the BOP benchmark for 6D object pose estimation.
Deep Model-Based 6D Pose Refinement in RGB
We present a novel approach for model-based 6D pose refinement in color data.

Distortion-Aware Convolutional Filters for Dense Prediction in Panoramic Images
There is a high demand of 3D data for 360° panoramic images and videos, pushed by the growing availability on the market of specialized hardware for both capturing (e. g., omnidirectional cameras) as well as visualizing in 3D (e. g., head mounted displays) panoramic images and videos.
 Ranked #10 on
Depth Estimation
on Stanford2D3D Panoramic
Ranked #10 on
Depth Estimation
on Stanford2D3D Panoramic
BOP: Benchmark for 6D Object Pose Estimation
We propose a benchmark for 6D pose estimation of a rigid object from a single RGB-D input image.
Fully-Convolutional Point Networks for Large-Scale Point Clouds
This work proposes a general-purpose, fully-convolutional network architecture for efficiently processing large-scale 3D data.
 Ranked #27 on
Semantic Segmentation
on ScanNet
Ranked #27 on
Semantic Segmentation
on ScanNet
Deep Learned Full-3D Object Completion from Single View
3D geometry is a very informative cue when interacting with and navigating an environment.
Human Motion Analysis with Deep Metric Learning
Nevertheless, we believe that traditional approaches such as L2 distance or Dynamic Time Warping based on hand-crafted local pose metrics fail to appropriately capture the semantic relationship across motions and, as such, are not suitable for being employed as metrics within these tasks.
Peeking Behind Objects: Layered Depth Prediction from a Single Image
While conventional depth estimation can infer the geometry of a scene from a single RGB image, it fails to estimate scene regions that are occluded by foreground objects.
Situation Assessment for Planning Lane Changes: Combining Recurrent Models and Prediction
One of the greatest challenges towards fully autonomous cars is the understanding of complex and dynamic scenes.
Webly Supervised Learning for Skin Lesion Classification
Within medical imaging, manual curation of sufficient well-labeled samples is cost, time and scale-prohibitive.

Guide Me: Interacting with Deep Networks
Interaction and collaboration between humans and intelligent machines has become increasingly important as machine learning methods move into real-world applications that involve end users.
Fast and Accurate Semantic Mapping through Geometric-based Incremental Segmentation
We propose an efficient and scalable method for incrementally building a dense, semantically annotated 3D map in real-time.
Predicting Multiple Actions for Stochastic Continuous Control
We introduce a new approach to estimate continuous actions using actor-critic algorithms for reinforcement learning problems.
SSD-6D: Making RGB-based 3D detection and 6D pose estimation great again
We present a novel method for detecting 3D model instances and estimating their 6D poses from RGB data in a single shot.
 Ranked #1 on
6D Pose Estimation using RGBD
on Tejani
Ranked #1 on
6D Pose Estimation using RGBD
on Tejani
Long Short-Term Memory Kalman Filters: Recurrent Neural Estimators for Pose Regularization
One-shot pose estimation for tasks such as body joint localization, camera pose estimation, and object tracking are generally noisy, and temporal filters have been extensively used for regularization.

6D Object Pose Estimation with Depth Images: A Seamless Approach for Robotic Interaction and Augmented Reality
To determine the 3D orientation and 3D location of objects in the surroundings of a camera mounted on a robot or mobile device, we developed two powerful algorithms in object detection and temporal tracking that are combined seamlessly for robotic perception and interaction as well as Augmented Reality (AR).
Long Short-Term Memory Kalman Filters:Recurrent Neural Estimators for Pose Regularization
One-shot pose estimation for tasks such as body joint localization, camera pose estimation, and object tracking are generally noisy, and temporal filters have been extensively used for regularization.
Learning without Prejudice: Avoiding Bias in Webly-Supervised Action Recognition
One of the main problems in webly-supervised learning is cleaning the noisy labeled data from the web.

CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction
Given the recent advances in depth prediction from Convolutional Neural Networks (CNNs), this paper investigates how predicted depth maps from a deep neural network can be deployed for accurate and dense monocular reconstruction.
Concurrent Segmentation and Localization for Tracking of Surgical Instruments
Real-time instrument tracking is a crucial requirement for various computer-assisted interventions.
Learning in an Uncertain World: Representing Ambiguity Through Multiple Hypotheses
In future prediction, for example, many distinct outcomes are equally valid.
An Octree-Based Approach towards Efficient Variational Range Data Fusion
Volume-based reconstruction is usually expensive both in terms of memory consumption and runtime.
Hashmod: A Hashing Method for Scalable 3D Object Detection
We present a scalable method for detecting objects and estimating their 3D poses in RGB-D data.
Deep Learning of Local RGB-D Patches for 3D Object Detection and 6D Pose Estimation
We present a 3D object detection method that uses regressed descriptors of locally-sampled RGB-D patches for 6D vote casting.
A Taxonomy and Library for Visualizing Learned Features in Convolutional Neural Networks
Over the last decade, Convolutional Neural Networks (CNN) saw a tremendous surge in performance.
Deeper Depth Prediction with Fully Convolutional Residual Networks
This paper addresses the problem of estimating the depth map of a scene given a single RGB image.
A Versatile Learning-Based 3D Temporal Tracker: Scalable, Robust, Online
This paper proposes a temporal tracking algorithm based on Random Forest that uses depth images to estimate and track the 3D pose of a rigid object in real-time.
Learning a Descriptor-Specific 3D Keypoint Detector
Keypoint detection represents the first stage in the majority of modern computer vision pipelines based on automatically established correspondences between local descriptors.
